CREATE SEARCH INDEX
Defines a new search index for an existing table.
cassandra.yaml
The location of the cassandra.yaml file depends on the type of installation:| Package installations | /etc/dse/cassandra/cassandra.yaml |
| Tarball installations | installation_location/resources/cassandra/conf/cassandra.yaml |
Synopsis
CREATE SEARCH INDEX [ IF NOT EXISTS ] ON [keyspace_name.]table_name
[ WITH [ COLUMNS column_list { option : value } [ , ... ] ]
[ [ AND ] PROFILES profile_name [ , ... ] ]
[ [ AND ] CONFIG { option:value } [ , ... ] ]
[ [ AND ] OPTIONS { option:value } [ , ... ] ] ] ;
If the CREATE SEARCH INDEX statement specifies no options, all columns are indexed using the default values.
| Syntax conventions | Description |
|---|---|
| UPPERCASE | Literal keyword. |
| Lowercase | Not literal. |
Italics |
Variable value. Replace with a user-defined value. |
[] |
Optional. Square brackets ( [] ) surround
optional command arguments. Do not type the square brackets. |
( ) |
Group. Parentheses ( ( ) ) identify a group to
choose from. Do not type the parentheses. |
| |
Or. A vertical bar ( | ) separates alternative
elements. Type any one of the elements. Do not type the vertical
bar. |
... |
Repeatable. An ellipsis ( ... ) indicates that
you can repeat the syntax element as often as required. |
'Literal string' |
Single quotation ( ' ) marks must surround
literal strings in CQL statements. Use single quotation marks to
preserve upper case. |
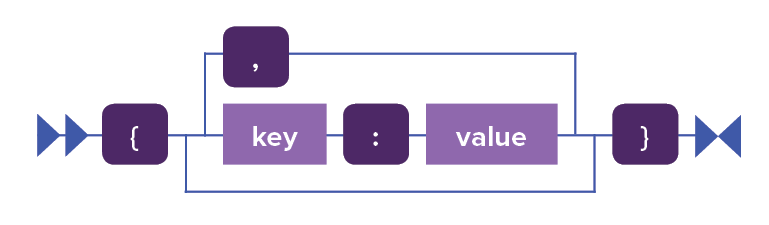
{ key : value
} |
Map collection. Braces ( { } ) enclose map
collections or key value pairs. A colon separates the key and the
value. |
<datatype1,datatype2> |
Set, list, map, or tuple. Angle brackets ( <
> ) enclose data types in a set, list, map, or tuple.
Separate the data types with a comma. |
cql_statement; |
End CQL statement. A semicolon ( ; ) terminates
all CQL statements. |
[--] |
Separate the command line options from the command arguments with
two hyphens ( -- ). This syntax is useful when
arguments might be mistaken for command line options. |
' <schema> ... </schema>
' |
Search CQL only: Single quotation marks ( ' )
surround an entire XML schema declaration. |
@xml_entity='xml_entity_type' |
Search CQL only: Identify the entity and literal value to overwrite the XML element in the schema and solrConfig files. |
EBNF
createSearchIndex ::= 'CREATE' 'SEARCH' 'INDEX' ('IF' 'NOT' 'EXISTS')?
'ON' tableName
('WITH' indexOptions)?
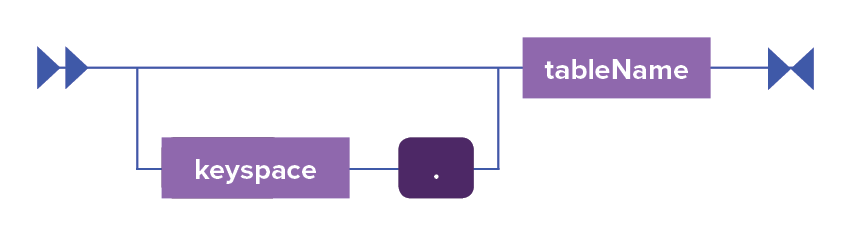
tableName ::= (keyspace '.')? table
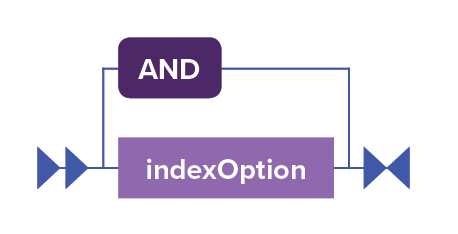
indexOptions ::= indexOption ('AND' indexOption)*
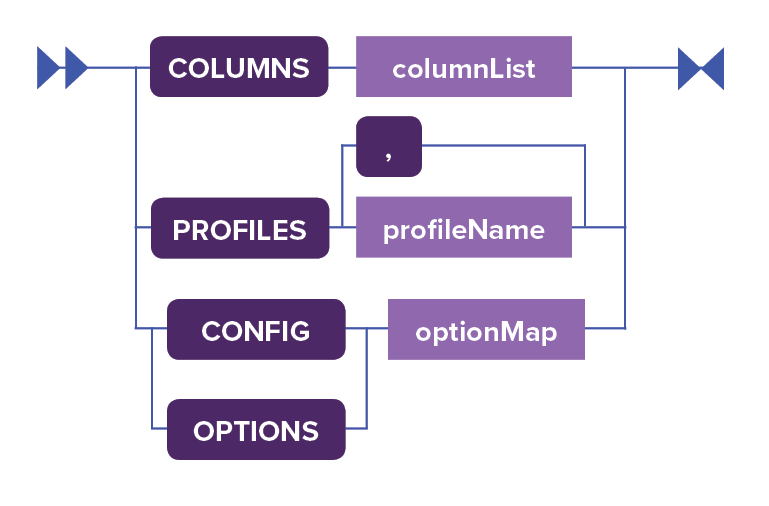
indexOption ::= 'COLUMNS' columnList
| 'PROFILES' profileName (',' profileName)*
| 'CONFIG' optionMap
| 'OPTIONS' optionMap
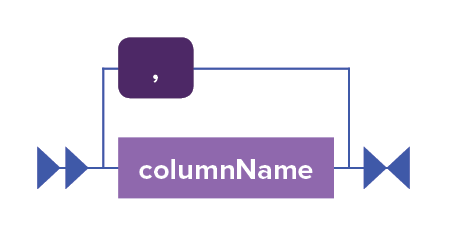
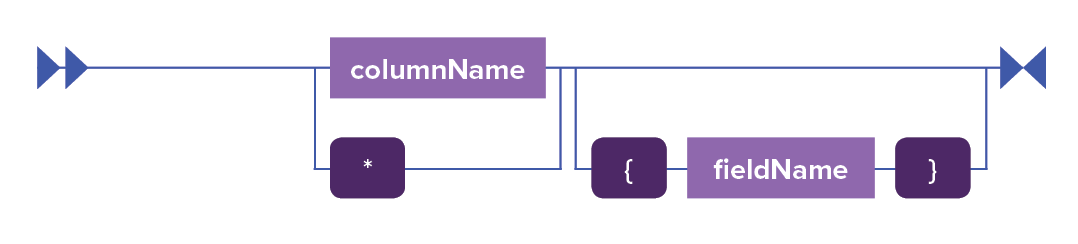
columnList ::= column (',' column)*
column ::= (columnName | '*')('{' optionMap '}')?
optionMap ::= '{' (optionName ':' optionValue (',' optionName ':'
optionValue)*)? '}'Railroad diagram:

COLUMNS
COLUMNS column_list { copyField : true | false },
column_list { docValues : true | false },
column_list { excluded : true | false },
column_list { indexed : true | false }- column_list
- A comma-separated list or * (for all columns). You can include tuple fields and
subfields. Any column not listed is excluded from the index by default, except PRIMARY
KEY columns, which must be indexed.
- A comma-separated list of all of the column_names, tuplefield, or tuplefield.subfield to include in the search index. When a subfield is selected for inclusion, parent fields are always included.
- For each column in the column_list, optionally specify true or false for copyField, docValues, excluded, or indexed.
- Asterisk (*) to select all columns.
COLUMNS column_name1, column_name2
COLUMNS column_name1, column_name2 {copyField:true} - copyField: (true | false)
- Set to true to create a new field copied from the specified columns with type
StrField. Duplicates the data from the original field into the new field. Use for columns that require both search and faceting.Default value is false.
- docValues: ( true | false)
- Creates a forward index on each specified column. Setting is only valid on Solr types
that extend TrieField, UUIDField, and StrField. Use on columns that are sorted or
grouped (faceted). Default is true for TrieField and UUIDField types and false StrField
types.
Due to SOLR-7264, setting docValues to true on a boolean field in the Solr schema does not work. A workaround for boolean docValues is to use 0 and 1 with a TrieIntField.
Note: Using spaceSavings profiles disables auto generation of DocValues. - excluded: (true | false)
- When using the COLUMNS option, exclude column from index:
- true - exclude the listed columns and all fields in the columns from the index.
- false - do not exclude the listed columns from the index. You must specify columns to include to include the columns in the index. Default when not specified.
- indexed: (true | false)
- When using the COLUMNS option:
- true - include the specified fields in the index. Default when not specified.
- false - exclude the specified fields from the index.
Important: Non-indexed columns are present in HTTP query results andsinglePassqueries only if they are included in the Solr schema.xml file. For more information, see Solr single-pass CQL queries.
PROFILES
PROFILES profile_name [, profile_name, ...]
- spaceSavingAll
- Applies all profiles.
- spaceSavingNoJoin
- Excludes the hidden partition key required for joins across tables on search queries from the index. When used table joins on search index queries are not allowed.
- spaceSavingSlowTriePrecision
- Sets trie fields precisionStep to '0', allowing for greater space saving but slower querying.
CONFIG
CONFIG { shortcut_name:value [, shortcut_name:value, ...] }- shortcuts
-
Shortcuts to configuration element values using SET:
autoCommitTimeDefault value is 10000.defaultQueryFieldName of the field. Default not set.Note: Use SET to add. Use DROP to remove.directoryFactoryCan be used as an alternative to the directoryFactoryClass option. The options are:- 'standard'
- 'encrypted'
filterCacheLowWaterMarkDefault is 1024.filterCacheHighWaterMarkDefault is 2048.directoryFactoryClassSpecifies the fully-qualified name of the directory factory. Use in place of the directoryFactory option for directory factories other than the standard or encrypted directory factory.mergeMaxThreadCountMust configure with mergeMaxMergeCount. The default is the number of tpc_cores as configured in cassandra.yaml.mergeMaxMergeCountMust configure with mergeMaxThreadCount. The default calculated value is:max(max(<maxThreadCount * 2>, <num_tokens * 8>), <maxThreadCount + 5>)
where num_tokens is the number of token ranges to assign to the virtual node (vnode) as configured in cassandra.yaml.ramBufferSizeDefault is 512.realtimeDefault is false.
OPTIONS
OPTIONS { option:value [, option:value, ...] }The
request options are boolean values: - recovery
-
- true - if the search core is unable to load due to corrupted index, recovers it by deleting and recreating the index. The deleteAll flag is set based on the recovery flag unless deleteAll is specifically set.
- false - no recovery. Default.
- reindex
-
- true - reindexes the data. Keeps the current index (accepting reads) while the new index is building. Default.
- false - does not reindex the data.
- lenient
-
- true - Silently ignores fields if you encounter an unsupported column type during schema autogeneration.
- false - Raise error if you encounter an unsupported column type during schema autogeneration.
Note: This option is no longer needed for SpatialRecursivePrefixTreeFieldType fields, which are now automatically indexed.
Examples
The search index is created with the wiki.solr keyspace and table, and the specified options.
CREATE SEARCH INDEX IF NOT EXISTS
ON wiki.solr
WITH COLUMNS id, body {excluded : false};CREATE SEARCH INDEX
ON wiki.solr
WITH CONFIG { realtime:true }
AND OPTIONS { reindex : false };Create search index with transparent data encryption (TDE)
CREATE SEARCH INDEX IF NOT EXISTS
ON wiki.solr
WITH COLUMNS c1,c2 {docValues:true}
AND PROFILES spaceSavingAll
AND CONFIG {directoryFactory:'encrypted'};CREATE SEARCH INDEX
ON wiki.solr
WITH COLUMNS * { docValues:true };CREATE SEARCH INDEX
ON wiki.solr
WITH COLUMNS field1 { indexed:true }, field2 { indexed:false };Non-indexed columns are included in present in HTTP query results and single pass query results. To exclude, use the excluded option.
Create search index with controls for tuple and UDT fields
CREATE SEARCH INDEX
ON wiki.solr
WITH COLUMNS tuplefield.field1 {docValues:true};Parent
fields are included since the subfield is selected for inclusion. Create search index to specify the columns to exclude from HTTP query results and single pass queries
CREATE SEARCH INDEX
ON wiki.solr
WITH COLUMNS field1 { excluded:true }, field2 { excluded:false };Excluded
columns are not present in HTTP query results, but non-indexed columns are included. Create search index with space saving no join option
CREATE SEARCH INDEX ON wiki.solr WITH PROFILES spaceSavingNoJoin;
The
example avoids indexing the _partitionKey field. See Identifying the partition key.