CQL quick reference
Provides a consolidated syntax list of Cassandra Query Language (CQL) commands for quick reference.
Provides a consolidated syntax list of Cassandra Query Language (CQL) commands for quick reference.
See this quick reference guide for other CQL versions: 5.1 | 6.7.
Download a printable CQL reference with the ten most frequently use CQL commands and a list of the CQL data types.
ALTER KEYSPACE
ALTER KEYSPACE keyspace_name
WITH REPLICATION = { replication_map }
[ AND DURABLE_WRITES = ( true | false ) ] ;
Learn more.
Example
Change the cycling keyspace to NetworkTopologyStrategy in
a single datacenter and turn off durable writes (not recommended). This example uses the
default datacenter name with a replication factor of 1.
ALTER KEYSPACE cycling
WITH REPLICATION = {
'class' : 'NetworkTopologyStrategy',
'SearchAnalytics' : 1 }
AND DURABLE_WRITES = false ;
ALTER MATERIALIZED VIEW
ALTER MATERIALIZED VIEW [keyspace_name.]view_name WITH table_options [ AND table_options ] ;Learn more.
Examples
This section uses the cyclist_base and cyclist_by_age-mv.
Modifying table properties
Add a comment and set the bloom filter properties:
ALTER MATERIALIZED VIEW cycling.cyclist_by_age WITH comment = 'A most excellent and useful view' AND bloom_filter_fp_chance = 0.02;
For an overview of properties that apply to materialized views, see table_options.
Modifying compression and compaction
ALTER MATERIALIZED VIEW cycling.cyclist_by_age
WITH compression = {
'sstable_compression' : 'DeflateCompressor',
'chunk_length_kb' : 64 }
AND compaction = {
'class': 'SizeTieredCompactionStrategy',
'max_threshold': 64};Changing caching
You can create and change caching properties using a property map.
NONE (the
default is ALL) and changes the rows_per_partition
property to 15.
ALTER MATERIALIZED VIEW cycling.cyclist_by_age
WITH caching = {
'keys' : 'NONE',
'rows_per_partition' : '15' };Viewing current materialized view properties
DESCRIBE MATERIALIZED VIEW cycling.cyclist_by_age
CREATE MATERIALIZED VIEW cycling.cyclist_by_age AS
SELECT age, cid, birthday, country, name
FROM cycling.cyclist_base
WHERE age IS NOT NULL AND cid IS NOT NULL
PRIMARY KEY (age, cid)
WITH CLUSTERING ORDER BY (cid ASC)
AND bloom_filter_fp_chance = 0.02
AND caching = {'keys': 'NONE', 'rows_per_partition': '15'}
AND comment = 'A most excellent and useful view'
AND compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy', 'max_threshold': '64', 'min_threshold': '4'}
AND compression = {'chunk_length_in_kb': '64', 'class': 'org.apache.cassandra.io.compress.DeflateCompressor'}
AND crc_check_chance = 1.0
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND speculative_retry = '99PERCENTILE';ALTER ROLE
ALTER ROLE role_name
[ WITH [ PASSWORD = 'role_password' ]
[ LOGIN = ( true | false ) ]
[ SUPERUSER = ( true | false ) ]
[ OPTIONS = { option_map } ] ] ;
Learn more.
Example
ALTER ROLE sandy WITH PASSWORD='bestTeam';
ALTER SEARCH INDEX CONFIG
ALTER SEARCH INDEX CONFIG ON [keyspace_name.]table_name ( ADD element_path [ attribute_list ] WITH $$ json_map $$ | SET element_identifier = 'value' | SET shortcut = value | DROP element_identifier | DROP shortcut ) ;Learn more.
Examples
The search index configuration is altered for the wiki.solr keyspace and table, and the specified options.
Enable encryption on search index
- Change the configuration
schema:
ALTER SEARCH INDEX CONFIG ON cycling.comments SET directoryFactory = 'encrypted';
- Verify the change is correct in the pending
schema:
DESC PENDING SEARCH INDEX CONFIG ON cycling.comments
- Make the configuration
active:
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <config> <luceneMatchVersion>LUCENE_6_0_1</luceneMatchVersion> <dseTypeMappingVersion>2</dseTypeMappingVersion> <directoryFactory class="solr.EncryptedFSDirectoryFactory" name="DirectoryFactory"/> <indexConfig> <rt>false</rt> </indexConfig> <jmx/> <updateHandler> <autoSoftCommit> <maxTime>10000</maxTime> </autoSoftCommit> </updateHandler> <query> <filterCache class="solr.SolrFilterCache" highWaterMarkMB="2048" lowWaterMarkMB="1024"/> <enableLazyFieldLoading>true</enableLazyFieldLoading> <useColdSearcher>true</useColdSearcher> <maxWarmingSearchers>16</maxWarmingSearchers> </query> <requestDispatcher> <requestParsers enableRemoteStreaming="true" multipartUploadLimitInKB="2048000"/> <httpCaching never304="true"/> </requestDispatcher> <requestHandler class="solr.SearchHandler" default="true" name="search"/> <requestHandler class="com.datastax.bdp.search.solr.handler.component.CqlSearchHandler" name="solr_query"/> <requestHandler class="solr.UpdateRequestHandler" name="/update"/> <requestHandler class="solr.UpdateRequestHandler" name="/update/csv" startup="lazy"/> <requestHandler class="solr.UpdateRequestHandler" name="/update/json" startup="lazy"/> <requestHandler class="solr.FieldAnalysisRequestHandler" name="/analysis/field" startup="lazy"/> <requestHandler class="solr.DocumentAnalysisRequestHandler" name="/analysis/document" startup="lazy"/> <requestHandler class="solr.admin.AdminHandlers" name="/admin/"/> <requestHandler class="solr.PingRequestHandler" name="/admin/ping"> <lst name="invariants"> <str name="qt">search</str> <str name="q">solrpingquery</str> </lst> <lst name="defaults"> <str name="echoParams">all</str> </lst> </requestHandler> <requestHandler class="solr.DumpRequestHandler" name="/debug/dump"> <lst name="defaults"> <str name="echoParams">explicit</str> <str name="echoHandler">true</str> </lst> </requestHandler> </config>
- Apply the configuration and rebuild the
index:
RELOAD SEARCH INDEX ON cycling.comments;
Auto soft commit max time
ALTER SEARCH INDEX CONFIG ON cycling.comments SET autoCommitTime = 10000;
RELOAD SEARCH INDEX ON cycling.comments;
Request handler
ALTER SEARCH INDEX CONFIG
ON cycling.comments
ADD requestHandler[@name='/elevate',@class='solr.SearchHandler', @startup='lazy']
WITH $$ {"defaults":[{"echoParams":"explicit"}],"last-components":["elevator"]} $$;RELOAD SEARCH INDEX ON cycling.comments;
<requestHandler name="/elevate" class="solr.SearchHandler"> <lst name="defaults"> <str name="echoParams">explicit</int> </lst> <arr name="last-components"> <str>elevator</str> </arr> </requestHandler>
ALTER SEARCH INDEX CONFIG ON cycling.comments SET indexConfig.mergePolicyFactory[@class='org.apache.solr.index.AutoExpungeDeletesTieredMergePolicyFactory'].bool[@name='mergeSingleSegments'] = true; ALTER SEARCH INDEX CONFIG ON cycling.comments SET indexConfig.mergePolicyFactory[@class='org.apache.solr.index.AutoExpungeDeletesTieredMergePolicyFactory'].int[@name='maxMergedSegmentMB'] = 1005; ALTER SEARCH INDEX CONFIG ON cycling.comments SET indexConfig.mergePolicyFactory[@class='org.apache.solr.index.AutoExpungeDeletesTieredMergePolicyFactory'].int[@name='forceMergeDeletesPctAllowed'] = 25;
RELOAD SEARCH INDEX ON cycling.comments;
Change the auto-commit time
ALTER SEARCH INDEX CONFIG ON cycling.comments SET autoCommitTime = 1000;
ALTER SEARCH INDEX SCHEMA
ALTER SEARCH INDEX SCHEMA ON [keyspace_name.]table_name
( ADD field column_name
| ADD element_path [ attribute_list ] WITH $$ json_map $$
| SET element_identifier = 'value'
| DROP field field_name
| DROP element_identifier ) ;
Learn more.
Examples
The search index schema is altered for the cycling.comments keyspace and
table, and the specified options.
For extensive information and examples on search indexes, including adding and dropping search index fields, field types, field classes, tuples, UDTs, and map columns, see Managing search index fields.
You must add the search index before you can alter it.
Add a new field using the element path and attribute list
fields. in ADD fields.field
fieldname is optional and
provides only cosmetic structure.ALTER SEARCH INDEX SCHEMA ON cycling.comments ADD fields.field[@name='fieldname', @type='StrField', @multiValued = 'false', @indexed='true'];
RELOAD SEARCH INDEX ON cycling.comments;
Add a table column to the index
ALTER SEARCH INDEX SCHEMA ON cycling.comments ADD FIELD record_id;
RELOAD SEARCH INDEX ON cycling.comments; REBUILD SEARCH INDEX ON cycling.comments;
Change a field name
ALTER SEARCH INDEX SCHEMA ON cycling.comments SET field[@name='fieldname']@name = 'anotherFieldName';
To apply the schema changes:
RELOAD SEARCH INDEX ON cycling.comments; REBUILD SEARCH INDEX ON cycling.comments;
Change the field type
ALTER SEARCH INDEX SCHEMA ON cycling.comments SET field[@name='fieldname']@type = 'UUIDField';
To apply the schema changes:
RELOAD SEARCH INDEX ON cycling.comments; REBUILD SEARCH INDEX ON cycling.comments;
Drop a field
ALTER SEARCH INDEX SCHEMA ON cycling.comments DROP field anotherFieldName;
RELOAD SEARCH INDEX ON cycling.comments; REBUILD SEARCH INDEX ON cycling.comments;
Set a field type and a text field
The first command sets the TextField type, which is required for the second
command that sets the text field:
ALTER SEARCH INDEX SCHEMA ON cycling.comments SET types.fieldType[@name='TextField']@class='org.apache.solr.schema.TextField'; ALTER SEARCH INDEX SCHEMA ON cycling.comments SET fields.field[@name='comment']@type='TextField';
RELOAD SEARCH INDEX ON cycling.comments; REBUILD SEARCH INDEX ON cycling.comments;
Drop a field and a field type
The first command drops the field from the search index and the second command drops the field type:
ALTER SEARCH INDEX SCHEMA ON cycling.comments DROP field comment; ALTER SEARCH INDEX SCHEMA ON cycling.comments DROP types.fieldType[@name='TextField'];
RELOAD SEARCH INDEX ON cycling.comments; REBUILD SEARCH INDEX ON cycling.comments;
Add a field type and a dynamic field
The first command adds the TextField type, which must exist before the
dynamic field is added by the second command:
ALTER SEARCH INDEX SCHEMA
ON cycling.comments
ADD types.fieldType[@class='org.apache.solr.schema.TextField', @name='TextField']
WITH '{"analyzer":{"class":"org.apache.lucene.analysis.standard.StandardAnalyzer"}}';
ALTER SEARCH INDEX SCHEMA
ON cycling.comments
ADD dynamicField[@name='*fieldname', @type='TextField'];
RELOAD SEARCH INDEX ON cycling.comments; REBUILD SEARCH INDEX ON cycling.comments;
ALTER TABLE
ALTER TABLE [keyspace_name.]table_name [ ADD ( column_definition | column_definition_list ) ] [ DROP ( column | column_list | COMPACT STORAGE ) ] [ RENAME column_name TO column_name ] [ WITH table_properties [ , ... ] ] ;Learn more.
Examples
This section uses the cyclist_races table.
Adding a column
ALTER TABLE cycling.cyclist_races ADD manager UUID;
ALTER TABLE cycling.cyclist_races ADD completed list<text>;
This operation does not validate the existing data.
- A column with the same name as an existing column.
- A static column if the table has no clustering columns.
Dropping a column
ALTER TABLE cycling.cyclist_races DROP manager;
DROP removes the column from the table definition. The column becomes unavailable for queries immediately after it is dropped. The database drops the column data during the next compaction.
- If you drop a column then re-add it, DataStax Enterprise does not restore the values written before the column was dropped.
- Do not re-add a dropped column that contained timestamps generated by a client; you can re-add columns with timestamps generated by the write time facility.
Renaming a column
ALTER TABLE cycling.race_times RENAME race_date TO date;
- You can only rename clustering columns, which are part of the primary key.
- You cannot rename the partition key because the partition key determines the data
storage location on a node. If a different partition name is required, the table must
be recreated and the data migrated.Note: There are many restrictions when using RENAME because SSTables are immutable. To change the state of the data on disk, everything must be rewritten.
- You can index a renamed column.
- You cannot rename a column if an index has been created on it.
- You cannot rename a static column.
Modifying table properties
- Single property name and value.
- Property map to set the names and values, as shown in the next section on compression and compaction.
ALTER TABLE cycling.cyclist_base WITH comment = 'basic cyclist information';
Enclose a text property value in single quotation marks.
Modifying compression and compaction
ALTER TABLE cycling.comments
WITH compression = {
'sstable_compression' : 'DeflateCompressor',
'chunk_length_kb' : 64 };Enclose the name of each key in single quotes. If the value is a string, enclose the string in quotes as well.
Changing caching
ALTER TABLE cycling.comments
WITH caching = {
'keys': 'NONE',
'rows_per_partition': 10 };Changing speculative retries
cyclist_base table to use 95th percentile for speculative
retry:ALTER TABLE cycling.cyclist_base WITH speculative_retry = '95percentile';
cyclist_base table to use 10 milliseconds for speculative
retry:ALTER TABLE cycling.cyclist_base WITH speculative_retry = '10ms';
Enabling and disabling background compaction
enabled property to
false to disable background
compaction:ALTER TABLE cycling.comments
WITH COMPACTION = {
'class': 'SizeTieredCompactionStrategy',
'enabled': 'false' };Reading extended compaction logs
Set the
log_all subproperty to true to collect in-depth
information about compaction activity on a node in a dedicated log file.
When extended compaction
is enabled, the database creates a file named compaction-%d.log
(%d is a sequential number) in home/logs.
-
type:enableLists SSTables that have been flushed previously.
{"type":"enable","keyspace":"test","table":"t","time":1470071098866,"strategies": [ {"strategyId":"0","type":"LeveledCompactionStrategy","tables":[],"repaired":true,"folders": ["/home/carl/oss/cassandra/bin/../data/data"]}, {"strategyId":"1","type":"LeveledCompactionStrategy","tables":[],"repaired":false,"folders": ["/home/carl/oss/cassandra/bin/../data/data"] } ] } type: flushLogs a flush event from a memtable to an SSTable on disk, including the compaction strategy for each table.
{"type":"flush","keyspace":"test","table":"t","time":1470083335639,"tables": [ {"strategyId":"1","table": {"generation":1,"version":"mb","size":106846362,"details": {"level":0,"min_token":"-9221834874718566760","max_token":"9221396997139245178"} } } ] }type: compactionLogs a compaction event.
{"type":"compaction","keyspace":"test","table":"t","time":1470083660267, "start":"1470083660188","end":"1470083660267","input": [ {"strategyId":"1","table": {"generation":1372,"version":"mb","size":1064979,"details": {"level":1,"min_token":"7199305267944662291", "max_token":"7323434447996777057"} } } ],"output": [ {"strategyId":"1","table": {"generation":1404,"version":"mb","size":1064306,"details": {"level":2,"min_token":"7199305267944662291", "max_token":"7323434447996777057"} } } ] }type: pendingLists the number of pending tasks for a compaction strategy.
{"type":"pending","keyspace":"test","table":"t","time":1470083447967, "strategyId":"1","pending":200}
Reviewing the table definition
DESC cycling.comments
CREATE TABLE cycling.comments (
id uuid,
created_at timestamp,
comment text,
commenter text,
record_id timeuuid,
PRIMARY KEY (id, created_at)
)
WITH CLUSTERING ORDER BY (created_at DESC)
AND bloom_filter_fp_chance = 0.01
AND caching = {'keys': 'NONE', 'rows_per_partition': '10'}
AND comment = ''
AND compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy',
'enabled': 'true', 'max_threshold': '32', 'min_threshold': '4'}
AND compression = {'chunk_length_in_kb': '64',
'class': 'org.apache.cassandra.io.compress.DeflateCompressor'}
AND crc_check_chance = 1.0
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND speculative_retry = '99PERCENTILE';ALTER TYPE
ALTER TYPE field_name ( ADD field_name cql_datatype | RENAME field_name TO new_field_name [ AND field_name TO new_field_name ... ] ) ;Learn more.
Examples
This section uses the fullname type.
Adding a field
ALTER TYPE cycling.fullname ADD middlename text;
Changing a field name
To change the name of a field in a user-defined type, use the RENAME old_name TO new_name syntax. Rename multiple fields by separating the directives with AND.
ALTER TYPE cycling.fullname RENAME middlename TO middle AND lastname TO last AND firstname TO first;
Verify the changes using describe:
DESC TYPE cycling.fullname
CREATE TYPE cycling.fullname (
first text,
last text,
middle text
);ALTER USER
ALTER USER user_name WITH PASSWORD 'user_password' [ ( SUPERUSER | NOSUPERUSER ) ] ;Learn more.
Examples
ALTER USER moss WITH PASSWORD 'bestReceiver';
ALTER USER moss SUPERUSER;
BATCH
BEGIN [ ( UNLOGGED | COUNTER ) ] BATCH [ USING TIMESTAMP [ epoch_microseconds ] ] dml_statement [ USING TIMESTAMP [ epoch_microseconds ] ] ; [ dml_statement [ USING TIMESTAMP [ epoch_microseconds ] ] [ ; ... ] ] APPLY BATCH ;Learn more.
Examples
This section uses the cyclist_expenses and popular_count tables.
Applying a client supplied timestamp to all DMLs
BEGIN BATCH USING TIMESTAMP 1481124356754405
INSERT INTO cycling.cyclist_expenses (
cyclist_name, expense_id, amount, description, paid
) VALUES (
'Vera ADRIAN', 2, 13.44, 'Lunch', true
);
INSERT INTO cycling.cyclist_expenses (
cyclist_name, expense_id, amount, description, paid
) VALUES (
'Vera ADRIAN', 3, 25.00, 'Dinner', true
);
APPLY BATCH;cqlsh:EXPAND ON
SELECT cyclist_name, expense_id, amount, WRITETIME(amount), description, WRITETIME(description), paid, WRITETIME(paid) FROM cycling.cyclist_expenses WHERE cyclist_name = 'Vera ADRIAN';
@ Row 1
------------------------+------------------
cyclist_name | Vera ADRIAN
expense_id | 2
amount | 13.44
writetime(amount) | 1481124356754405
description | Lunch
writetime(description) | 1481124356754405
paid | True
writetime(paid) | 1481124356754405
@ Row 2
------------------------+------------------
cyclist_name | Vera ADRIAN
expense_id | 3
amount | 25
writetime(amount) | 1481124356754405
description | Dinner
writetime(description) | 1481124356754405
paid | True
writetime(paid) | 1481124356754405
(2 rows)If any DML statement in the batch uses compare-and-set (CAS) logic, an error is returned.
For example, the following batch with the CAS IF NOT EXISTS option
returns an error:
BEGIN BATCH USING TIMESTAMP 1481124356754405
INSERT INTO cycling.cyclist_expenses (
cyclist_name, expense_id, amount, description, paid
) VALUES (
'Vera ADRIAN', 2, 13.44, 'Lunch', true
);
INSERT INTO cycling.cyclist_expenses (
cyclist_name, expense_id, amount, description, paid
) VALUES (
'Vera ADRIAN', 3, 25.00, 'Dinner', false
) IF NOT EXISTS;
APPLY BATCH;
InvalidRequest: Error from server: code=2200 [Invalid query]
message="Cannot provide custom timestamp for conditional BATCH"Batching conditional updates
Batch conditional updates introduced as lightweight transactions. However, a batch containing conditional updates can operate only within a single partition, because the underlying Paxos implementation only works at partition-level granularity. If one statement in a batch is a conditional update, the conditional logic must return true, or the entire batch fails. If the batch contains two or more conditional updates, all the conditions must return true, or the entire batch fails.
IF NOT EXISTS conditional
clause.BEGIN BATCH
INSERT INTO cycling.cyclist_expenses (
cyclist_name, expense_id
) VALUES (
'Joe WALLS', 1
) IF NOT EXISTS;
INSERT INTO cycling.cyclist_expenses (
cyclist_name, expense_id, amount, description, paid
) VALUES (
'Joe WALLS', 1, 8, 'burrito', false
);
APPLY BATCH;Conditional
batches cannot provide custom timestamps. UPDATE and
DELETE statements within a conditional batch cannot use
IN conditions to filter rows.A continuation of this example shows how to use a static column with conditional updates in batch.
Batching counter updates
COUNTER option because, unlike other
writes in DataStax Enterprise, a counter update is not an idempotent operation.
BEGIN COUNTER BATCH UPDATE cycling.popular_count SET popularity = popularity + 1 WHERE id = 6ab09bec-e68e-48d9-a5f8-97e6fb4c9b47; UPDATE cycling.popular_count SET popularity = popularity + 125 WHERE id = 6ab09bec-e68e-48d9-a5f8-97e6fb4c9b47; UPDATE cycling.popular_count SET popularity = popularity - 64 WHERE id = 6ab09bec-e68e-48d9-a5f8-97e6fb4c9b47; APPLY BATCH;
Counter batches cannot include non-counter columns in the DML statements, just as a non-counter batch cannot include counter columns. Counter batch statements cannot provide custom timestamps.
COMMIT SEARCH INDEX
COMMIT SEARCH INDEX ON [keyspace_name.]table_name ;Learn more.
Examples
COMMIT SEARCH INDEX ON cycling.comments;
CREATE AGGREGATE
CREATE [ OR REPLACE ] AGGREGATE [ IF NOT EXISTS ] [keyspace_name.]aggregate_name (cql_type) SFUNC udf_name STYPE cql_type FINALFUNC udf_name INITCOND init_value [ DETERMINISTIC ] ;Learn more.
Examples
- Create a function with a state parameter as a tuple that counts the rows (by
incrementing 1 for each record) in the first position and finds the total by adding the
current row value to the existing subtotal the second position, and returns the updated
state.
CREATE OR REPLACE FUNCTION cycling.avgState ( state tuple<int, bigint>, val int ) CALLED ON NULL INPUT RETURNS tuple<int, bigint> LANGUAGE java AS $$ if (val != null) { state.setInt(0, state.getInt(0) + 1); state.setLong(1, state.getLong(1) + val.intValue()); } return state; $$ ;Note: Use a simple test to verify that your function works properly.CREATE TABLE cycling.test_avg ( id int PRIMARY KEY, state frozen<tuple<int, bigint>>, val int ); INSERT INTO cycling.test_avg ( id, state, val ) VALUES ( 1, (6, 9949), 51 ); INSERT INTO cycling.test_avg ( id, state, val ) VALUES ( 2, (79, 10000), 9999 ); SELECT state, avgstate(state, val), val FROM cycling.test_avg;
The first value was incremented by one and the second value is the results of the initial state value and val.
state | cycling.avgstate(state, val) | val -------------+------------------------------+------ (6, 9949) | (7, 10000) | 51 (79, 10000) | (80, 19999) | 9999 - Create a function that divides the total value for the selected column by the number
of
records.
CREATE OR REPLACE FUNCTION cycling.avgFinal ( state tuple<int,bigint> ) CALLED ON NULL INPUT RETURNS double LANGUAGE java AS $$ double r = 0; if (state.getInt(0) == 0) return null; r = state.getLong(1); r /= state.getInt(0); return Double.valueOf(r); $$ ; - Create the user-defined aggregate to calculate the average value in the
column:
CREATE OR REPLACE AGGREGATE cycling.average ( int ) SFUNC avgState STYPE tuple<int,bigint> FINALFUNC avgFinal INITCOND (0, 0) ;
- Test the function using a select
statement:
SELECT cycling.average(cyclist_time_sec) FROM cycling.team_average WHERE team_name = 'UnitedHealthCare Pro Cycling Womens Team' AND race_title = 'Amgen Tour of California Women''s Race presented by SRAM - Stage 1 - Lake Tahoe > Lake Tahoe';
CREATE CUSTOM INDEX
CREATE CUSTOM INDEX [ IF NOT EXISTS ] [ index_name ]
ON [keyspace_name.]table_name (column_name)
USING 'org.apache.cassandra.index.sasi.SASIIndex'
[ WITH OPTIONS = { option_map } ] ;
Learn more.
Examples
All examples use the cycling.cyclist_name table.
Creating a SASI PREFIX index on a column
firstname:CREATE CUSTOM INDEX fn_prefix ON cycling.comments (commenter) USING 'org.apache.cassandra.index.sasi.SASIIndex';
The SASI mode PREFIX is the default, and does not need to be
specified.
Creating a SASI CONTAINS index on a column
Create an SASI
index on the column
firstname:
CREATE CUSTOM INDEX fn_contains
ON cycling.comments (comment)
USING 'org.apache.cassandra.index.sasi.SASIIndex'
WITH OPTIONS = { 'mode': 'CONTAINS' };The
SASI mode CONTAINS must be specified.Creating a SASI SPARSE index on a column
age:CREATE CUSTOM INDEX fn_sparse
ON cycling.comments (record_id)
USING 'org.apache.cassandra.index.sasi.SASIIndex'
WITH OPTIONS = { 'mode': 'SPARSE' };SPARSE must be specified. This mode is used for dense number
columns that store timestamps or millisecond sensor readings.Creating a SASI PREFIX index on a column using the non-tokenizing analyzer
age:CREATE CUSTOM INDEX fn_notcasesensitive
ON cycling.comments (comment)
USING 'org.apache.cassandra.index.sasi.SASIIndex'
WITH OPTIONS = {
'analyzer_class': 'org.apache.cassandra.index.sasi.analyzer.NonTokenizingAnalyzer',
'case_sensitive': 'false'};Creating a SASI analyzing index on a column
comments:CREATE CUSTOM INDEX stdanalyzer_idx
ON cycling.comments (comment)
USING 'org.apache.cassandra.index.sasi.SASIIndex'
WITH OPTIONS = { 'mode': 'CONTAINS',
'analyzer_class': 'org.apache.cassandra.index.sasi.analyzer.StandardAnalyzer',
'analyzed': 'true',
'tokenization_skip_stop_words': 'and, the, or',
'tokenization_enable_stemming': 'true',
'tokenization_normalize_lowercase': 'true',
'tokenization_locale': 'en' }
;CREATE FUNCTION
CREATE [ OR REPLACE ] FUNCTION [ IF NOT EXISTS ] [keyspace_name.]function_name (argument_list [ , ... ]) ( CALLED | RETURNS NULL ) ON NULL INPUT RETURNS cql_data_type [ DETERMINISTIC ] [ MONOTONIC [ ON argument_name ] ] LANGUAGE ( java | javascript ) AS $$ code_block $$ ;Learn more.
Examples
Use Java to create FLOG function
CALLED ON NULL INPUT ensures that the function will always be
executed.CREATE OR REPLACE FUNCTION cycling.fLog (
input double
)
CALLED ON NULL INPUT
RETURNS double
LANGUAGE java AS
$$
return Double.valueOf(Math.log(input.doubleValue()));
$$
;Use Javascript to create SQL-like LEFT function
CREATE OR REPLACE FUNCTION cycling.left (
column text, num int
)
RETURNS NULL ON NULL INPUT
RETURNS text
LANGUAGE javascript AS
$$
column.substring(0, num)
$$
;SELECT left(firstname, 1), lastname FROM cycling.cyclist_name;
cycling.left(firstname, 1) | lastname
----------------------------+-----------------
A | FRAME
null | MATTHEWS
null | VOS
P | TIRALONGO
M | VOS
S | KRUIKSWIJK
A | VAN DER BREGGENCREATE INDEX
CREATE INDEX [ IF NOT EXISTS ] index_name ON [keyspace_name.]table_name ([ ( KEYS | FULL ) ] column_name) (ENTRIES column_name);Learn more.
Examples
Creating an index on a clustering column
Define a table having a composite partition key, and then create an index on a clustering column.
CREATE TABLE cycling.rank_by_year_and_name ( race_year int, race_name text, cyclist_name text, rank int, PRIMARY KEY ((race_year, race_name), rank) );
CREATE INDEX rank_idx ON cycling.rank_by_year_and_name (rank);
Creating an index on a set or list collection
Create an index on a set or list collection column as you would any other column. Enclose
the name of the collection column in parentheses at the end of the CREATE
INDEX statement. For example, add a collection of teams to the
cyclist_career_teams table to index the data in the teams set.
CREATE TABLE cycling.cyclist_career_teams ( id UUID PRIMARY KEY, lastname text, teams set<text> );
CREATE INDEX teams_idx ON cycling.cyclist_career_teams (teams) ;
Creating an index on map keys
{'nation':'CANADA' }To index map keys, use the KEYS keyword and map name in nested
parentheses:
CREATE INDEX team_year_idx ON cycling.cyclist_teams ( KEYS (teams) );
To query the table, you can use CONTAINS KEY in WHERE clauses.
SELECT * FROM cycling.cyclist_teams WHERE teams CONTAINS KEY 2015;
The example returns cyclist teams that have an entry for the year 2015.
id | firstname | lastname | teams
--------------------------------------+-----------+------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
cb07baad-eac8-4f65-b28a-bddc06a0de23 | Elizabeth | ARMITSTEAD | {2011: 'Team Garmin - Cervelo', 2012: 'AA Drink - Leontien.nl', 2013: 'Boels:Dolmans Cycling Team', 2014: 'Boels:Dolmans Cycling Team', 2015: 'Boels:Dolmans Cycling Team'}
5b6962dd-3f90-4c93-8f61-eabfa4a803e2 | Marianne | VOS | {2014: 'Rabobank-Liv Woman Cycling Team', 2015: 'Rabobank-Liv Woman Cycling Team'}
Creating an index on map entries
You can create an index on map entries. An ENTRIES index can be created
only on a map column of a table that doesn't have an existing index.
ENTRIES keyword and map name in
nested
parentheses:CREATE INDEX blist_idx ON cycling.birthday_list (ENTRIES(blist));
To query the map entries in the table, use a WHERE clause with the map
name and a value.
SELECT * FROM cycling.birthday_list WHERE blist['age'] = '23';
The example finds cyclists who are the same age.
cyclist_name | blist
------------------+----------------------------------------------------------
Claudio HEINEN | {'age': '23', 'bday': '27/07/1992', 'nation': 'GERMANY'}
Laurence BOURQUE | {'age': '23', 'bday': '27/07/1992', 'nation': 'CANADA'}
SELECT * FROM cycling.birthday_list WHERE blist['nation'] = 'NETHERLANDS'; cyclist_name | blist
---------------+--------------------------------------------------------------
Luc HAGENAARS | {'age': '28', 'bday': '27/07/1987', 'nation': 'NETHERLANDS'}
Toine POELS | {'age': '52', 'bday': '27/07/1963', 'nation': 'NETHERLANDS'}
Creating an index on map values
VALUES keyword and map name in
nested
parentheses:CREATE INDEX blist_values_idx ON cycling.birthday_list (VALUES(blist));To query the table, use a WHERE clause with the map name and the value it
contains.
SELECT * FROM cycling.birthday_list WHERE blist CONTAINS 'NETHERLANDS'; cyclist_name | blist
---------------+--------------------------------------------------------------
Luc HAGENAARS | {'age': '28', 'bday': '27/07/1987', 'nation': 'NETHERLANDS'}
Toine POELS | {'age': '52', 'bday': '27/07/1963', 'nation': 'NETHERLANDS'}
Creating an index on the full content of a frozen collection
You can create an index on a full FROZEN collection. A
FULL index can be created on a set, list, or map column of a table that
doesn't have an existing index.
Create an index on the full content of a FROZEN
list. The table in this example stores the number of Pro wins, Grand Tour
races, and Classic races that a cyclist has competed in.
CREATE TABLE cycling.race_starts (cyclist_name text PRIMARY KEY, rnumbers FROZEN<LIST<int>>);
FULL keyword and collection name in
nested parentheses. For example, index the frozen list
rnumbers.CREATE INDEX rnumbers_idx ON cycling.race_starts (FULL(rnumbers));
To query the table, use a WHERE clause with the collection name and
values:
SELECT * FROM cycling.race_starts WHERE rnumbers = [39,7,14];
cyclist_name | rnumbers ----------------+------------- John DEGENKOLB | [39, 7, 14]
CREATE KEYSPACE
CREATE KEYSPACE [ IF NOT EXISTS ] keyspace_name
WITH REPLICATION = { replication_map }
[ AND DURABLE_WRITES = ( true | false ) ] ;
Learn more.
Examples
Create a keyspace for a single node evaluation cluster
CREATE KEYSPACE cycling
WITH REPLICATION = {
'class' : 'SimpleStrategy',
'replication_factor' : 1
};Create a keyspace NetworkTopologyStrategy on an evaluation cluster
CREATE KEYSPACE cycling
WITH REPLICATION = {
'class' : 'NetworkTopologyStrategy',
'datacenter1' : 1 }
;datacenter1
is the default datacenter name. To display the datacenter name, use dsetool status.dsetool statusReturns the data center name, rack name, host name and IP address.
DC: Cassandra Workload: Cassandra Graph: no
======================================================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Owns Token Rack Health [0,1]
0
UN 10.0.0.15 67.44 MiB ? -9223372036854775808 rack1 0.90
UN 10.0.0.110 766.4 KiB ? 0 rack2 0.90
Note: you must specify a keyspace to get ownership information.Create the cycling keyspace in an environment with mutliple data centers
CREATE KEYSPACE "Cycling"
WITH REPLICATION = {
'class' : 'NetworkTopologyStrategy',
'boston' : 3 , // Datacenter 1
'seattle' : 2 , // Datacenter 2
'tokyo' : 2 // Datacenter 3
};Disabling durable writes
CREATE KEYSPACE cycling
WITH REPLICATION = {
'class' : 'NetworkTopologyStrategy',
'datacenter1' : 3
}
AND DURABLE_WRITES = false ;CREATE MATERIALIZED VIEW
CREATE MATERIALIZED VIEW [ IF NOT EXISTS ] [keyspace_name.]view_name
AS SELECT [ (column_list) ]
FROM [keyspace_name.]table_name
WHERE column_name IS NOT NULL [ AND column_name IS NOT NULL ... ]
[ AND relation [ AND ... ] ]
PRIMARY KEY (column_list)
[ WITH [ table_properties ]
[ [ AND ] CLUSTERING ORDER BY (cluster_column_name order_option) ] ] ;
Learn more.
Examples
This section shows example scenarios that illustrate the use of materialized views.Basic example of a materialized view
Thiscyclist_base table is used in the first example
scenario:CREATE TABLE IF NOT EXISTS cycling.cyclist_base ( cid UUID PRIMARY KEY, name text, age int, birthday date, country text );The following materialized view
cyclist_by_age uses the base table
cyclist_base. The WHERE clause ensures that only rows
whose age and cid columns are non-NULL are added to the
materialized view. In the materialized view, age is the partition key, and
cid is the clustering column. In the base table, cid is
the partition
key.CREATE MATERIALIZED VIEW cycling.cyclist_by_age AS
SELECT age, cid, birthday, country, name
FROM cycling.cyclist_base
WHERE age IS NOT NULL
AND cid IS NOT NULL
PRIMARY KEY (age, cid)
WITH CLUSTERING ORDER BY (cid ASC)
AND caching = { 'keys' : 'ALL', 'rows_per_partition' : '100' }
AND comment = 'Based on table cyclist';
The results of this
query:SELECT * FROM cycling.cyclist_by_age;are:
age | cid | birthday | country | name -----+--------------------------------------+------------+---------------+--------------------- 28 | 6ab09bec-e68e-48d9-a5f8-97e6fb4c9b47 | 1987-06-07 | Netherlands | Steven KRUIKSWIJK 19 | 1c526849-d3a2-42a3-bcf9-7903c80b3d16 | 1998-12-23 | Australia | Kanden GROVES 19 | 410919ef-bd1b-4efa-8256-b0fd8ab67029 | 1999-01-04 | Uzbekistan | Iskandarbek SHODIEV 18 | 15a116fc-b833-4da6-ab9a-4a7775752836 | 1997-08-19 | United States | Adrien COSTA 18 | 18f471bf-f631-4bc4-a9a2-d6f6cf5ea503 | 1997-03-29 | Netherlands | Bram WELTEN 18 | ffdfa2a7-5fc6-49a7-bfdc-3fcdcfdd7156 | 1997-02-08 | Netherlands | Pascal EENKHOORN 22 | e7ae5cf3-d358-4d99-b900-85902fda9bb0 | 1993-06-18 | New Zealand | Alex FRAME 27 | c9c9c484-5e4a-4542-8203-8d047a01b8a8 | 1987-09-04 | Brazil | Cristian EGIDIO 27 | d1aad83b-be60-47a4-bd6e-069b8da0d97b | 1987-09-04 | Germany | Johannes HEIDER 20 | 862cc51f-00a1-4d5a-976b-a359cab7300e | 1994-09-04 | Denmark | Joakim BUKDAL 38 | 220844bf-4860-49d6-9a4b-6b5d3a79cbfb | 1977-07-08 | Italy | Paolo TIRALONGO 29 | 96c4c40d-58c8-4710-b73f-681e9b1f70ae | 1989-04-20 | Australia | Benjamin DYBALL (12 rows)
Using a materialized view to perform queries that are not possible on a base table
The following scenario shows how to use a materialized view to perform queries that are not possible on a base table unless ALLOW FILTERING is used. ALLOW FILTERING is not recommended because of the performance degradation. This table stores the cycling team mechanic information:CREATE TABLE IF NOT EXISTS cycling.mechanic ( emp_id int, dept_id int, name text, age int, birthdate date, PRIMARY KEY (emp_id, dept_id) );The table contains these rows:
emp_id | dept_id | age | birthdate | name
--------+---------+-----+------------+------------
5 | 3 | 25 | 1996-10-04 | Lisa SMITH
1 | 1 | 21 | 1992-06-18 | Fred GREEN
2 | 1 | 22 | 1993-01-15 | John SMITH
4 | 2 | 24 | 1995-08-19 | Jack JONES
3 | 2 | 23 | 1994-02-07 | Jane DOE
(5 rows)This
materialized view selects the columns from the previous table and contains a different primary
key from the table:
CREATE MATERIALIZED VIEW IF NOT EXISTS cycling.mechanic_view AS
SELECT emp_id, dept_id, name, age, birthdate
FROM cycling.mechanic
WHERE emp_id IS NOT NULL
AND dept_id IS NOT NULL
AND name IS NOT NULL
AND age IS NOT NULL
AND birthdate IS NOT NULL
PRIMARY KEY (age, emp_id, dept_id);This
query retrieves the rows where the age is
21:SELECT * FROM cycling.mechanic_view WHERE age = 21;The previous query cannot be run on the base table without ALLOW FILTERING. The output from the previous query is as follows:
age | emp_id | dept_id | birthdate | name -----+--------+---------+------------+------------ 21 | 1 | 1 | 1992-06-18 | Fred GREEN (1 rows)
CREATE ROLE
CREATE ROLE [ IF NOT EXISTS ] role_name [ WITH [ SUPERUSER = ( true | false ) ] [ [ AND ] LOGIN = ( true | false ) ] ( WITH PASSWORD 'role_password' | WITH HASHED PASSWORD 'hashed_role_password' ) [ [ AND ] OPTIONS = { option_map } ] ] ;Learn more.
Examples
Creating a login account
- Create a login role for coach.
CREATE ROLE coach WITH PASSWORD = 'All4One2day!' AND LOGIN = true;
If a hashed password is used, useWITH HASHED PASSWORD:Internal authentication requires the role to have a password or hashed password. The hashed password was generated with the DSE toolhash_password -p All4One2day!. - Verify that the account works by logging in:
LOGIN coach
- Enter the password at the prompt.
Password: - The cqlsh prompt includes the role name:
coach@cqlsh>
Creating a role
A best practice when using internal authentication is to create separate roles for permissions and login accounts. Once a role has been created it can be assigned as permission to another role, see GRANT for more details. Roles for externally authenticators users are mapped to the user's group name. LDAP mapping is case sensitive.
Create a role for the cycling keyspace administrator, that is a role that has full
permission to only the cycling keyspace.
- Create the role:
CREATE ROLE cycling_admin;
At this point the role has no permissions. Manage permissions usingGRANTandREVOKE.Note: A role can only modify permissions of another role and can only modify (GRANTorREVOKE) role permissions that it also has. - Assign the role full access to the cycling keyspace:
GRANT ALL PERMISSIONS on KEYSPACE cycling to cycling_admin;
- Now assign the role to the coach.
GRANT cycling_admin TO coach;
This allows you to manage the permissions of all cycling administrators by modifying thecycling_adminrole. - View the coach's permissions.
LIST ALL PERMISSIONS OF coach;
Changing a password
ALTER ROLE sandy WITH PASSWORD='bestTeam';or with a hashed password:
CREATE SEARCH INDEX
CREATE SEARCH INDEX [ IF NOT EXISTS ] ON [keyspace_name.]table_name
[ WITH [ COLUMNS column_list { option : value } [ , ... ] ]
[ [ AND ] PROFILES profile_name [ , ... ] ]
[ [ AND ] CONFIG { option:value } [ , ... ] ]
[ [ AND ] OPTIONS { option:value } [ , ... ] ] ] ;
Learn more.
Examples
The search index is created with the wiki.solr keyspace and table, and the specified options.
CREATE SEARCH INDEX IF NOT EXISTS
ON wiki.solr WITH COLUMNS id, body { excluded : false };CREATE SEARCH INDEX
ON wiki.solr
WITH CONFIG { realtime:true }
AND OPTIONS { reindex : false };Create search index with transparent data encryption (TDE)
CREATE SEARCH INDEX IF NOT EXISTS
ON wiki.solr
WITH COLUMNS c1,c2 { docValues:true }
AND PROFILES spaceSavingAll
AND CONFIG { directoryFactory:'encrypted' };CREATE SEARCH INDEX
ON wiki.solr WITH COLUMNS * { docValues:true };CREATE SEARCH INDEX
ON wiki.solr
WITH COLUMNS field1 { indexed:true }, field2 { indexed:false };Non-indexed columns are included in present in HTTP query results and single pass query results. To exclude, use the excluded option.
Create search index with controls for tuple and UDT fields
CREATE SEARCH INDEX
ON wiki.solr
WITH COLUMNS tuplefield.field1 { docValues:true };Parent
fields are included since the subfield is selected for inclusion. Create search index to specify the columns to exclude from HTTP query results and singlePass queries
CREATE SEARCH INDEX
ON wiki.solr
WITH COLUMNS field1 { excluded:true }, field2 { excluded:false };Excluded
columns are not present in HTTP query results, but non-indexed columns are included. Create search index to specify the columns to exclude from HTTP query results and single pass queries
CREATE SEARCH INDEX
ON wiki.solr
WITH COLUMNS field1 { excluded:true }, field2 { excluded:false };Excluded
columns are not present in HTTP query results, but non-indexed columns are included. Create search index with space saving no join option
CREATE SEARCH INDEX ON wiki.solr WITH PROFILES spaceSavingNoJoin;
The
example avoids indexing the _partitionKey field. See Identifying the partition key.
CREATE TABLE
CREATE TABLE [ IF NOT EXISTS ] [keyspace_name.]table_name ( column_definition [ , ... ] | PRIMARY KEY (column_list) ) [ WITH [ table_options ] [ [ AND ] CLUSTERING ORDER BY [ clustering_column_name order ] ] [ [ AND ] ID = 'table_hash_tag' ] ] ;Learn more.
cassandra.yaml
The location of the cassandra.yaml file depends on the type of installation:| Package installations | /etc/dse/cassandra/cassandra.yaml |
| Tarball installations | installation_location/resources/cassandra/conf/cassandra.yaml |
Creating a table with a frozen UDT
race_winners table
that has a frozen user-defined type
(UDT):CREATE TABLE cycling.race_winners ( cyclist_name FROZEN<fullname>, race_name text, race_position int, PRIMARY KEY (race_name, race_position));
See Creating a user-defined type for information on creating UDTs. UDTs can be created unfrozen if only non-collection fields are used in the user-defined type creation. If the table is created with an unfrozen UDT, then individual field values can be updated and deleted.
Creating a table with UUID as the primary key
cyclist_name table with
UUID as the primary
key:CREATE TABLE cycling.cyclist_name ( id UUID PRIMARY KEY, lastname text, firstname text );
Creating a compound primary key
cyclist_category table and store the data in reverse
order:CREATE TABLE cycling.cyclist_category ( category text, points int, id UUID, lastname text, PRIMARY KEY (category, points)) WITH CLUSTERING ORDER BY (points DESC);
Creating a composite partition key
CREATE TABLE cycling.rank_by_year_and_name ( race_year int, race_name text, cyclist_name text, rank int, PRIMARY KEY ((race_year, race_name), rank) );
Creating a table with a CDC log
cyclist_id
table:CREATE TABLE cycling.cyclist_id ( lastname text, firstname text, age int, id UUID, PRIMARY KEY ((lastname, firstname), age) );
Storing data in descending order
CREATE TABLE cycling.cyclist_category ( category text, points int, id UUID, lastname text, PRIMARY KEY (category, points)) WITH CLUSTERING ORDER BY (points DESC);
Restoring from the table ID for commit log replay
CREATE TABLE cycling.cyclist_emails ( userid text PRIMARY KEY, id UUID, emails set<text> ) WITH ID='1bb7516e-b140-11e8-96f8-529269fb1459';
id column of system_schema.tables. For
example:SELECT id FROM system_schema.tables WHERE keyspace_name = 'cycling' AND table_name = 'cyclist_emails';
To perform a point-in-time restoration of the table, see Restoring a backup to a specific point-in-time.
CREATE TYPE
CREATE TYPE [ IF NOT EXISTS ] [keyspace_name.]type_name (field_name cql_datatype [ , field_name cql_datatype ... ]) ;Learn more.
Example
This example creates a user-defined type cycling.basic_info that consists
of personal data about an individual cyclist.
CREATE TYPE cycling.basic_info (
birthday timestamp,
nationality text,
height text,
weight text
);
After defining the UDT, you can create a table that has columns with the UDT. CQL collection columns and other columns support the use of user-defined types, as shown in Using CQL examples.
DELETE
DELETE [ column_name [ term ] [ , ... ] ] FROM [keyspace_name.]table_name [ USING TIMESTAMP timestamp_value ] WHERE PK_column_conditions [ ( IF EXISTS | IF static_column_conditions ) ] ;Learn more.
Examples
Delete data in specified columns from a row
Delete the data in specific columns by listing them after the DELETE
command, separated by commas. Change the data in first and last name columns to null for
the cyclist specified by id.
DELETE firstname, lastname FROM cycling.cyclist_name WHERE id = e7ae5cf3-d358-4d99-b900-85902fda9bb0;
CREATE TABLE cycling.cyclist_name ( id UUID PRIMARY KEY, lastname text, firstname text );
id | firstname | lastname
--------------------------------------+-----------+-----------------
e7ae5cf3-d358-4d99-b900-85902fda9bb0 | Alex | FRAME
fb372533-eb95-4bb4-8685-6ef61e994caa | Michael | MATTHEWS
5b6962dd-3f90-4c93-8f61-eabfa4a803e2 | Marianne | VOS
220844bf-4860-49d6-9a4b-6b5d3a79cbfb | Paolo | TIRALONGO
6ab09bec-e68e-48d9-a5f8-97e6fb4c9b47 | Steven | KRUIKSWIJK
e7cd5752-bc0d-4157-a80f-7523add8dbcd | Anna | VAN DER BREGGEN
(6 rows) id | firstname | lastname
--------------------------------------+-----------+-----------------
e7ae5cf3-d358-4d99-b900-85902fda9bb0 | null | null
fb372533-eb95-4bb4-8685-6ef61e994caa | Michael | MATTHEWS
5b6962dd-3f90-4c93-8f61-eabfa4a803e2 | Marianne | VOS
220844bf-4860-49d6-9a4b-6b5d3a79cbfb | Paolo | TIRALONGO
6ab09bec-e68e-48d9-a5f8-97e6fb4c9b47 | Steven | KRUIKSWIJK
e7cd5752-bc0d-4157-a80f-7523add8dbcd | Anna | VAN DER BREGGEN
(6 rows)Delete an entire row
Entering no column names after DELETE removes the entire matching row.
Remove a cyclist entry from the cyclist_name table and return an error if
no rows match by specifying IF EXISTS.
DELETE FROM cycling.cyclist_name WHERE id = e7ae5cf3-d358-4d99-b900-85902fda9bb0 IF EXISTS;
True (if a row with this primary
key does exist), standard output displays a table like the following:
[applied]
-----------
True id | firstname | lastname
--------------------------------------+-----------+-----------------
fb372533-eb95-4bb4-8685-6ef61e994caa | Michael | MATTHEWS
5b6962dd-3f90-4c93-8f61-eabfa4a803e2 | Marianne | VOS
220844bf-4860-49d6-9a4b-6b5d3a79cbfb | Paolo | TIRALONGO
6ab09bec-e68e-48d9-a5f8-97e6fb4c9b47 | Steven | KRUIKSWIJK
e7cd5752-bc0d-4157-a80f-7523add8dbcd | Anna | VAN DER BREGGEN
(5 rows)Delete a row based on a static column condition
The IF condition limits the WHERE clause, allowing
selection based on values in non-PRIMARY KEY columns, such as first and last name. This
example removes the cyclist record if the first and last names do not match.
DELETE FROM cycling.cyclist_name WHERE id = fb372533-eb95-4bb4-8685-6ef61e994caa IF firstname = 'Michael' AND lastname = 'Smith';
[applied] | firstname | lastname
-----------+-----------+----------
False | Michael | MATTHEWSConditionally deleting data from a column
Use the IF or IF EXISTS clauses to conditionally delete data from columns. Deleting column data conditionally is similar to making an UPDATE conditionally.
DELETE id FROM cycling.cyclist_id WHERE lastname = 'JONES' and firstname = 'Bram' IF EXISTS;
False and the command
fails. In this case, standard output looks
like: [applied]
-----------
FalseDELETE id FROM cycling.cyclist_id WHERE lastname = 'WELTEN' AND firstname = 'Bram' IF age = 20;
False in the [applied] column and also displays
information about the condition that
failed: [applied] | age
-----------+-----
False | 18Deleting one or more rows
The WHERE clause specifies which row or rows to delete from a specified table.
DELETE FROM cycling.cyclist_name WHERE id = 6ab09bec-e68e-48d9-a5f8-97e6fb4c9b47;
id | firstname | lastname
--------------------------------------+-----------+-----------------
fb372533-eb95-4bb4-8685-6ef61e994caa | Michael | MATTHEWS
5b6962dd-3f90-4c93-8f61-eabfa4a803e2 | Marianne | VOS
220844bf-4860-49d6-9a4b-6b5d3a79cbfb | Paolo | TIRALONGO
e7cd5752-bc0d-4157-a80f-7523add8dbcd | Anna | VAN DER BREGGEN
(4 rows)To delete more than one row, use the keyword IN and supply a list of comma-separated values in parentheses:
DELETE FROM cycling.cyclist_name WHERE id IN ( 5b6962dd-3f90-4c93-8f61-eabfa4a803e2, 220844bf-4860-49d6-9a4b-6b5d3a79cbfb );
IN predicates on non-primary keys is not supported. id | firstname | lastname
--------------------------------------+-----------+-----------------
fb372533-eb95-4bb4-8685-6ef61e994caa | Michael | MATTHEWS
e7cd5752-bc0d-4157-a80f-7523add8dbcd | Anna | VAN DER BREGGEN
(2 rows)Deleting old data using a timestamp
The TIMESTAMP is an integer representing microseconds. Use TIMESTAMP to identify data to delete. The query deletes any rows from a partition older than the timestamp.
DELETE firstname, lastname FROM cycling.cyclist_name USING TIMESTAMP 1318452291034 WHERE lastname = 'VOS';
Deleting from a collection set, list, or map
sponsorship:DELETE sponsorship FROM cycling.race_sponsors WHERE race_name = 'Giro d''Italia';
To delete an element from a list, specify the column_name followed by the list index position in square brackets:
DELETE sponsorship[2] FROM cycling.race_sponsors WHERE race_year=2018 AND race_name='Tour de France' ;
list requires an internal read. In addition, the client-side
application could only discover the indexed position by reading the whole list and
finding the values to remove, adding additional latency to the operation. If another
thread or client prepends elements to the list before the operation is done,
incorrect data will be removed.UPDATE command with a subtraction operator to
remove a list element in a safer and faster manner is recommended. See List fields.DELETE teams[2014] FROM cycling.cyclist_teams WHERE id = 5b6962dd-3f90-4c93-8f61-eabfa4a803e2;
DROP AGGREGATE
DROP AGGREGATE [ IF EXISTS ] [keyspace_name.]aggregate_name [ (argument_name [ , ... ]) ] ;Learn more.
Examples
Drop the avgState aggregate from the cycling keyspace.
DROP AGGREGATE IF EXISTS cycling.avgState;
DROP FUNCTION
DROP FUNCTION [ IF EXISTS ] [keyspace_name.]function_name [ (argument_name [ , ... ]) ] ;Learn more.
Examples
Drops the UDF from the cycling keyspace.
DROP FUNCTION IF EXISTS cycling.fLog;
DROP INDEX
DROP INDEX [ IF EXISTS ] [keyspace.]index_name ;Learn more.
Example
Drop the index rank_idx from the
cycling.rank_by_year_and_name table.
DROP INDEX IF EXISTS cycling.rank_idx;
DROP KEYSPACE
DROP KEYSPACE [ IF EXISTS ] keyspace_name ;Learn more.
Example
DROP KEYSPACE cycling IF EXISTS;
DROP MATERIALIZED VIEW
DROP MATERIALIZED VIEW [ IF EXISTS ] [keyspace_name.]view_name ;Learn more.
Example
Drop the cyclist_by_age materialized view from the
cyclist keyspace.
DROP MATERIALIZED VIEW IF EXISTS cycling.cyclist_by_age;
DROP ROLE
DROP ROLE [ IF EXISTS ] role_name ;Learn more.
Examples
Drop the team manager role.
DROP ROLE IF NOT EXISTS team_manager;
DROP SEARCH INDEX CONFIG
DROP SEARCH INDEX ON [keyspace_name.]table_name
OPTIONS { option : value [ , option : value , ... ] } ;
Learn more.
Examples
The search index is dropped for the wiki.solr keyspace and table, and the specified options.
Delete the resources associated with the search index
DROP SEARCH INDEX ON wiki.solr;
Keep the resources associated with the search index
DROP SEARCH INDEX ON wiki.solr WITH OPTIONS { deleteResources:false };DROP TABLE
DROP TABLE [ IF EXISTS ] [keyspace_name.]table_name ;Learn more.
Example
cyclist_name
table:DROP TABLE IF EXISTS cycling.cyclist_name;
DROP TYPE
DROP TYPE [ IF EXISTS ] [keyspace_name.]type_name ;Learn more.
Examples
DROP TYPE IF EXISTS cycling.basic_info;
InvalidRequest: Error from server: code=2200 [Invalid query] message="Cannot drop user type cycling.basic_info as it is still used by table cycling.cyclist_stats"DROP TABLE IF EXISTS cycling.cyclist_stats;
DROP TYPE IF EXISTS cycling.basic_info;
GRANT
GRANT permission ON object TO role_name ;Learn more.
Examples
In most environments, user authentication is handled by a plug-in that verifies the user credentials against an external directory service such as LDAP. For simplicity, the following examples use internal users.
Manage object permissions
AUTHORIZE to allow a role to manage access control of specific resources.- Allow role to grant any permission type, including
AUTHORIZE, on all objects in the cycling keyspace:GRANT AUTHORIZE ON KEYSPACE cycling TO cycling_admin;
Warning: This makes the role a superuser in the cycling keyspace because roles can modify their own permissions as well as roles that they inherit permissions from. - Allow the sam role to assign permission to run queries and
change data in the cycling
keyspace:
GRANT AUTHORIZE FOR SELECT, MODIFY ON KEYSPACE cycling TO sam;
Tip: Thesamrole cannot grant other permissions such asAUTHORIZE,AUTHORIZE FOR ...,ALTER,CREATE,DESCRIBE, andDROPto another role.
Access to data resources
Use the data resource permissions to manage access to keyspaces, tables, rows, and types.
GRANT ALL PERMISSIONS ON KEYSPACE cycling TO cycling_admin;
SELECT
statements and modify data on all tables in the cycling
keyspace:GRANT SELECT, MODIFY ON KEYSPACE cycling TO coach;
ALTER
KEYSPACE statements on the cycling keyspace, and also ALTER
TABLE, CREATE INDEX and DROP INDEX statements
on all tables in cycling
keyspace:GRANT ALTER ON KEYSPACE cycling TO coach;
SELECT
statements on rows that contain 'Sprint' in cycling.cyclist_category
table:GRANT SELECT ON 'Sprint' ROWS IN cycling.cyclist_category TO martin;
To view permissions see LIST PERMISSIONS.
INSERT
INSERT INTO [keyspace_name.]table_name
[ column_list VALUES column_values ]
[ IF NOT EXISTS ]
[ USING [ TTL seconds ] [ [ AND ] TIMESTAMP epoch_in_microseconds ] ] ;
Learn more.
Examples
Specifying TTL and TIMESTAMP
Insert a cyclist name using both a TTL and timestamp.
INSERT INTO cycling.cyclist_name ( id, lastname, firstname ) VALUES ( 6ab09bec-e68e-48d9-a5f8-97e6fb4c9b47, 'KRUIKSWIJK', 'Steven' ) USING TTL 86400 AND TIMESTAMP 123456789;
- Time-to-live (TTL) in seconds
- Timestamp in microseconds since epoch
Inserting values into a collection (set and map)
set for the cyclist
VOS. The set is defined in the table as teams
set<text>.INSERT INTO cycling.cyclist_career_teams (
id,lastname,teams
) VALUES (
5b6962dd-3f90-4c93-8f61-eabfa4a803e2,
'VOS',
{
'Rabobank-Liv Woman Cycling Team',
'Rabobank-Liv Giant',
'Rabobank Women Team',
'Nederland bloeit'
}
);map named teams that lists two
recent team memberships for the cyclist VOS. The map is defined in the
table as teams map<int,
text>.INSERT INTO cycling.cyclist_teams (
id, firstname, lastname, teams
) VALUES (
5b6962dd-3f90-4c93-8f61-eabfa4a803e2,
'Marianne',
'VOS',
{
2015 : 'Rabobank-Liv Woman Cycling Team',
2014 : 'Rabobank-Liv Woman Cycling Team'
}
);The size of one item in a collection is limited to 64K.
To insert data into a collection column of a user-defined type, enclose components of the type in parentheses within the curly brackets, as shown in Using a user-defined type.
Inserting a row only if it does not already exist
Add IF NOT EXISTS to the command to ensure that the operation is not performed if a row with the same primary key already exists:
INSERT INTO cycling.cyclist_name ( id, lastname, firstname ) VALUES ( c4b65263-fe58-4846-83e8-f0e1c13d518f, 'RATTO', 'Rissella' ) IF NOT EXISTS;
true in the
[applied] column of the results. For example:
[applied]
-----------
Truefalse in the [applied] column and returns the values
for the existing row. For
example: [applied] | id | firstname | lastname
-----------+--------------------------------------+-----------+----------
False | c4b65263-fe58-4846-83e8-f0e1c13d518f | Rissella | RATTOLIST PERMISSIONS
LIST ( ALL PERMISSIONS | permission_list ) [ ON resource_name ] [ OF role_name ] [ NORECURSIVE ] ;Learn more.
Example
All permissions for all roles and resources
LIST ALL PERMISSIONS;
Individual role permissions
LIST ALL PERMISSIONS OF sam;
role | username | resource | permission | granted | restricted | grantable ------+----------+--------------------+------------+---------+------------+----------- sam | sam | <keyspace cycling> | SELECT | False | False | True sam | sam | <keyspace cycling> | MODIFY | False | False | True (2 rows)
All permissions on a resource
LIST ALL PERMISSIONS ON cycling.cyclist_name;
role | username | resource | permission | granted | restricted | grantable
-----------------+-----------------+--------------------+------------+---------+------------+-----------
coach | coach | <keyspace cycling> | ALTER | True | False | False
coach | coach | <keyspace cycling> | SELECT | True | False | False
coach | coach | <keyspace cycling> | MODIFY | True | False | False
cycling_admin | cycling_admin | <keyspace cycling> | CREATE | True | False | False
cycling_admin | cycling_admin | <keyspace cycling> | ALTER | True | False | False
cycling_admin | cycling_admin | <keyspace cycling> | DROP | True | False | False
cycling_admin | cycling_admin | <keyspace cycling> | SELECT | True | False | False
cycling_admin | cycling_admin | <keyspace cycling> | MODIFY | True | False | False
cycling_admin | cycling_admin | <keyspace cycling> | AUTHORIZE | True | False | False
cycling_admin | cycling_admin | <keyspace cycling> | DESCRIBE | True | False | False
cycling_analyst | cycling_analyst | <keyspace cycling> | SELECT | True | False | False
dantest1 | dantest1 | <keyspace cycling> | AUTHORIZE | True | False | False
db_admin | db_admin | <keyspace cycling> | SELECT | False | True | False
db_admin | db_admin | <keyspace cycling> | MODIFY | False | True | False
martin | martin | <all keyspaces> | CREATE | False | True | False
martin | martin | <keyspace cycling> | CREATE | True | False | False
role_admin | role_admin | <keyspace cycling> | SELECT | False | True | False
role_admin | role_admin | <keyspace cycling> | MODIFY | False | True | False
sam | sam | <keyspace cycling> | SELECT | False | False | True
sam | sam | <keyspace cycling> | MODIFY | False | False | True
team_manager | team_manager | <keyspace cycling> | MODIFY | True | False | False
(21 rows)LIST ROLES
LIST ROLES [ OF role_name ] [ NORECURSIVE ] ;Learn more.
Examples
All roles
LIST ROLES;
(Internal Role Management only) Roles assigned to a role
LIST ROLES OF coach;
role | super | login | options
---------------+-------+-------+---------
coach | False | False | {}
cycling_admin | False | True | {}
(2 rows)REBUILD SEARCH INDEX
REBUILD SEARCH INDEX ON [keyspace_name.]table_name
[ WITH OPTIONS { deleteAll : ( true | false ) } ] ;
Learn more.
Examples
The search index is rebuilt and reloaded for the wiki.solr keyspace and
table.
REBUILD SEARCH INDEX ON wiki.solr WITH OPTIONS { deleteAll:true };RELOAD SEARCH INDEX ON wiki.solr;
RELOAD SEARCH INDEX
RELOAD SEARCH INDEX ON [keyspace_name.]table_name ;Learn more.
Examples
The search index schema and configuration are reloaded for the wiki.solr keyspace.
RELOAD SEARCH INDEX ON wiki.solr;
RESTRICT ROWS
RESTRICT permission ON [keyspace_name.]table_name TO role_name ;Learn more.
Examples
RESTRICT MODIFY, SELECT ON KEYSPACE cycling TO role_admin;
REVOKE
REVOKE permission ON resource_name FROM role_name ;Learn more.
Example
REVOKE SELECT, MODIFY ON KEYSPACE cycling FROM coach;
Because of inheritance, the user can perform SELECT queries on
cycling.name if one of these conditions is met:
- The user is a superuser.
- The user has
SELECTonALL KEYSPACESpermissions. - The user has
SELECTon the cycling keyspace.
ALTER commands
in the cycling
keyspace:REVOKE ALTER ON KEYSPACE cycling FROM coach;
SELECT
SELECT selectors FROM [keyspace_name.]table_name [ WHERE [ primary_key_conditions ] [ AND ] [ index_conditions ] [ GROUP BY column_name [ , ... ] ] [ ORDER BY PK_column_name [ , ... ] ( ASC | DESC ) ] [ ( LIMIT N | PER PARTITION LIMIT N ) ] [ ALLOW FILTERING ] ;Learn more.
Examples
Using a column alias
When your selection list includes functions or other complex expressions, use aliases to
make the output more readable. This example applies aliases to the
dateOf(created_at) and blobAsText(content)
functions:
SELECT event_id, dateOf(created_at) AS creation_date, blobAsText(content) AS content FROM timeline;
The output labels these columns with more understandable names:
event_id | creation_date | content
-------------------------+--------------------------+----------------
550e8400-e29b-41d4-a716 | 2013-07-26 10:44:33+0200 | Some stuff
(1 rows)The number of rows returned by the query is shown at the bottom of the output.
Specifying the source table using FROM
The following example SELECT statement returns the number of rows in
the IndexInfo table in the system keyspace:
SELECT COUNT(*) FROM system.IndexInfo;
Controlling the number of rows returned using LIMIT
The LIMIT option sets the maximum number of rows that the query
returns:
SELECT lastname FROM cycling.cyclist_name LIMIT 50000;
Even if the query matches 105,291 rows, the database only returns the first 50,000.
The cqlsh shell has a default row limit of 10,000. The DSE server and
native protocol do not limit the number of returned rows, but they apply a timeout to
prevent malformed queries from causing system instability.
Selecting partitions
partition_column = value
partition_column IN ( value1, value2 [ , ... ] )
AND:partition_column1 = value1 AND partition_column2 = value2 [ AND ... ] )
Controlling the number of rows returned using PER PARTITION LIMIT
The PER PARTITION LIMIT option sets the maximum number of rows that the
query returns from each partition. For example, create a table that sorts data into more
than one partition.
CREATE TABLE cycling.rank_by_year_and_name (
race_year int,
race_name text,
cyclist_name text,
rank int,
PRIMARY KEY ((race_year, race_name), rank)
);After inserting data, the table contains these rows:
race_year | race_name | rank | cyclist_name
-----------+--------------------------------------------+------+----------------------
2014 | 4th Tour of Beijing | 1 | Phillippe GILBERT
2014 | 4th Tour of Beijing | 2 | Daniel MARTIN
2014 | 4th Tour of Beijing | 3 | Johan Esteban CHAVES
2014 | Tour of Japan - Stage 4 - Minami > Shinshu | 1 | Daniel MARTIN
2014 | Tour of Japan - Stage 4 - Minami > Shinshu | 2 | Johan Esteban CHAVES
2014 | Tour of Japan - Stage 4 - Minami > Shinshu | 3 | Benjamin PRADES
2015 | Giro d'Italia - Stage 11 - Forli > Imola | 1 | Ilnur ZAKARIN
2015 | Giro d'Italia - Stage 11 - Forli > Imola | 2 | Carlos BETANCUR
2015 | Tour of Japan - Stage 4 - Minami > Shinshu | 1 | Benjamin PRADES
2015 | Tour of Japan - Stage 4 - Minami > Shinshu | 2 | Adam PHELAN
2015 | Tour of Japan - Stage 4 - Minami > Shinshu | 3 | Thomas LEBASTo get the top two racers in every race year and race name, use the
SELECT statement with PER PARTITION LIMIT 2.
SELECT *
FROM cycling.rank_by_year_and_name
PER PARTITION LIMIT 2;Output:
race_year | race_name | rank | cyclist_name
-----------+--------------------------------------------+------+----------------------
2014 | 4th Tour of Beijing | 1 | Phillippe GILBERT
2014 | 4th Tour of Beijing | 2 | Daniel MARTIN
2014 | Tour of Japan - Stage 4 - Minami > Shinshu | 1 | Daniel MARTIN
2014 | Tour of Japan - Stage 4 - Minami > Shinshu | 2 | Johan Esteban CHAVES
2015 | Giro d'Italia - Stage 11 - Forli > Imola | 1 | Ilnur ZAKARIN
2015 | Giro d'Italia - Stage 11 - Forli > Imola | 2 | Carlos BETANCUR
2015 | Tour of Japan - Stage 4 - Minami > Shinshu | 1 | Benjamin PRADES
2015 | Tour of Japan - Stage 4 - Minami > Shinshu | 2 | Adam PHELANFiltering data using WHERE
The WHERE clause introduces one or more
relations that filter the rows returned by SELECT.
The column specifications
- One or more members of the partition key of the table.
- A clustering column, only if the relation is preceded by other relations that specify all columns in the partition key.
- A column that is indexed using CREATE INDEX.
WHERE clause, refer to a column
using the actual name, not an alias.Filtering on the partition key
id as the table's partition
key:CREATE TABLE cycling.cyclist_career_teams ( id UUID PRIMARY KEY, lastname text, teams set<text> );In this example, the SELECT statement includes in the partition key, so the WHERE clause can use the
id column:SELECT id, lastname, teams FROM cycling.cyclist_career_teams WHERE id = 5b6962dd-3f90-4c93-8f61-eabfa4a803e2;
Filtering on a clustering column
Use a relation on a clustering column only if it is preceded by relations that reference all the elements of the partition key.
Example:
CREATE TABLE cycling.cyclist_points ( id UUID, race_points int, firstname text, lastname text, race_title text, PRIMARY KEY (id, race_points) );
SELECT SUM(race_points) FROM cycling.cyclist_points WHERE id = e3b19ec4-774a-4d1c-9e5a-decec1e30aac AND race_points > 7;
system.sum(race_points)
-------------------------
195
(1 rows)ALLOW FILTERING to filter a non-indexed cluster
column. ALLOW FILTERING because it impacts
performance.race_start_date is a clustering column without a secondary
index.Example:
CREATE TABLE cycling.calendar ( race_id int, race_name text, race_start_date timestamp, race_end_date timestamp, PRIMARY KEY (race_id, race_start_date, race_end_date) );
SELECT * FROM cycling.calendar WHERE race_start_date = '2015-06-13' ALLOW FILTERING;
Output:
race_id | race_start_date | race_end_date | race_name
---------+---------------------------------+---------------------------------+----------------
102 | 2015-06-13 07:00:00.000000+0000 | 2015-06-13 07:00:00.000000+0000 | Tour de Suisse
103 | 2015-06-13 07:00:00.000000+0000 | 2015-06-17 07:00:00.000000+0000 | Tour de FranceIt is possible to combine the partition key and a clustering column in a single relation. For details, see Comparing clustering columns.
Filtering on indexed columns
A WHERE clause in a SELECT on an indexed table must include at least one equality relation to the indexed column. For details, see Indexing a column.
Using the IN operator
Use
IN, an equals condition operator, to list multiple possible values for
a column. This example selects two columns, first_name and
last_name, from three rows having employee ids (primary key) 105, 107,
or
104:
SELECT first_name, last_name FROM emp WHERE empID IN (105, 107, 104);
The list can consist of a range of column values separated by commas.
Using IN to filter on a compound or composite primary key
IN condition on the last column of the
partition key only when it is preceded by equality conditions for all preceding columns of
the partition key. For
example:CREATE TABLE parts ( part_type text, part_name text, part_num int, part_year text, serial_num text, PRIMARY KEY ((part_type, part_name), part_num, part_year) );
SELECT *
FROM parts
WHERE part_type='alloy'
AND part_name='hubcap'
AND part_num = 1249
AND part_year IN ('2010', '2015');IN, you can omit the equality test for clustering columns other
than the last. But this usage may require the use of ALLOW FILTERING, so
it impacts performance. For
example:SELECT *
FROM parts
WHERE part_num = 123456
AND part_year IN ('2010', '2015')
ALLOW FILTERING;CQL
supports an empty list of values in the IN clause, useful in Java Driver
applications when passing empty arrays as arguments for the IN
clause.
When not to use IN
Under
most conditions, using IN in relations on the partition key is not
recommended. To process a list of values, the SELECT may have to query
many nodes, which degrades performance. For example, consider a single local datacenter
cluster with 30 nodes, a replication factor of 3, and a consistency level of
LOCAL_QUORUM. A query on a single partition key query goes out to two
nodes. But if the SELECT uses the IN condition, the
operation can involve more nodes — up to 20, depending on where the keys fall in the token
range.
Using IN for clustering columns is safer. See Cassandra Query Patterns: Not using the “in” query for
multiple partitions for additional logic about using IN.
Filtering on collections
Your
query can retrieve a collection in its entirety. It can also index the collection column,
and then use the CONTAINS condition in the WHERE clause
to filter the data for a particular value in the collection, or use CONTAINS
KEY to filter by key. This example features a collection of tags in the
playlists table. The query can index the tags, then filter on
'blues' in the tag set.
SELECT album, tags FROM playlists WHERE tags CONTAINS 'blues';
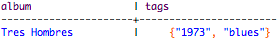
SELECT * FROM playlists WHERE venue CONTAINS 'The Fillmore';
SELECT * FROM playlists WHERE venue CONTAINS KEY '2014-09-22 22:00:00-0700';
Filtering a map's entries
CREATE INDEX blist_idx ON cycling.birthday_list (ENTRIES(blist));
SELECT * FROM cycling.birthday_list WHERE blist['age'] = '23';
Filtering a full frozen collection
FROZEN collection (set, list, or map). The query retrieves rows that
fully match the collection's values.
CREATE INDEX rnumbers_idx ON cycling.race_starts (FULL(rnumbers));
SELECT * FROM cycling.race_starts WHERE rnumbers = [39, 7, 14];
Range relations
DataStax Enterprise supports greater-than and less-than comparisons, but for a given partition key, the conditions on the clustering column are restricted to the filters that allow selection of a contiguous set of rows.
CREATE TABLE ruling_stewards ( steward_name text, king text, reign_start int, event text, PRIMARY KEY (steward_name, king, reign_start) );
king were not a component of the primary key, you
would need to create an index on king to use this
query:SELECT * FROM ruling_stewards WHERE king = 'Brego' AND reign_start >= 2450 AND reign_start < 2500 ALLOW FILTERING;
steward_name | king | reign_start | event
--------------+-------+-------------+--------------------
Boromir | Brego | 2477 | Attacks continue
Cirion | Brego | 2489 | Defeat of Balchoth
(2 rows)To
allow selection of a contiguous set of rows, the WHERE clause must
apply an equality condition to the king component of the primary key. The
ALLOW FILTERING clause is also required.
ALLOW FILTERING provides the capability to query the clustering columns
using any condition.
Only use ALLOW FILTERING for development. When you attempt a
potentially expensive query, such as searching a range of rows, DSE displays this
message:
Bad Request: Cannot execute this query as it might involve data
filtering and thus may have unpredictable performance. If you want
to execute this query despite the performance unpredictability,
use ALLOW FILTERING.To run this type of query, use ALLOW FILTERING, and restrict the
output to n rows using LIMIT n. For example:
SELECT * FROM ruling_stewards WHERE king = 'none' AND reign_start >= 1500 AND reign_start < 3000 LIMIT 10 ALLOW FILTERING;
Using LIMIT does not prevent all problems caused by ALLOW
FILTERING. In this example, if there are no entries without a value for
king, the SELECT scans the entire table, no
matter what the LIMIT is.
It is not necessary to use LIMIT with ALLOW
FILTERING, and LIMIT can be used by itself. But
LIMIT can prevent a query from ranging over all partitions in a
datacenter, or across multiple datacenters.
Using compound primary keys and sorting results
These restrictions apply when using anORDER BY clause with a compound primary
key: - Only include clustering columns in the
ORDER BYclause. - In the
WHEREclause, provide all the partition key values and clustering column values that precede the column(s) in theORDER BYclause. In 6.0 and later, the columns specified in theORDER BYclause must be an ordered subset of the columns of the clustering key; however, columns restricted by the equals operator (=) or a single-valuedINrestriction can be skipped. - When sorting multiple columns, the columns must be listed in the same order in the
ORDER BYclause as they are listed in thePRIMARY KEYclause of the table definition. - Sort ordering is limited. For example, if your table definition uses
CLUSTERING ORDER BY (start_month ASC, start_day ASC), then you can useORDER BY start_day, racein your query (ASCis the default). You can also reverse the sort ordering if you apply it to all of the columns; for example,ORDER BY start_day DESC, race DESC. - Refer to a column using the actual name, not an alias.
For example, set up the playlists table
(which uses a compound primary key), and use this query to get information about a
particular playlist, ordered by song_order. You do not need to include the ORDER
BY column in the select
expression.
SELECT * FROM playlists WHERE id = 62c36092-82a1-3a00-93d1-46196ee77204 ORDER BY song_order DESC LIMIT 50;
Output:

Or, create an index on playlist artists, and use this query to get titles of Fu Manchu songs on the playlist:
CREATE INDEX ON playlists(artist);
SELECT album, title FROM playlists WHERE artist = 'Fu Manchu';
Output:

Grouping results
The GROUP BY
clause condenses the selected rows that share the same values for a set of columns into a
group. A GROUP BY clause can contain:
- Partition key columns and clustering columns.
- A deterministic monotonic function, including a user-defined function (UDF), on the
last clustering column specified in the
GROUP BYclause. TheFLOOR()function is monotonic when the duration and start time parameters are constants. - A deterministic aggregate.
race_times_summary
table:CREATE TABLE cycling.race_times_summary ( race_date date, race_time time, PRIMARY KEY (race_date, race_time) );The table contains these rows:
race_date | race_time
------------+--------------------
2019-03-21 | 10:01:18.000000000
2019-03-21 | 10:15:20.000000000
2019-03-21 | 11:15:38.000000000
2019-03-21 | 12:15:40.000000000
2018-07-26 | 10:01:18.000000000
2018-07-26 | 10:15:20.000000000
2018-07-26 | 11:15:38.000000000
2018-07-26 | 12:15:40.000000000
2017-04-14 | 10:01:18.000000000
2017-04-14 | 10:15:20.000000000
2017-04-14 | 11:15:38.000000000
2017-04-14 | 12:15:40.000000000
(12 rows)race_date column
values:SELECT race_date, race_time FROM cycling.race_times_summary GROUP BY race_date;
race_date column value are grouped together
into one row in the query output. Three rows are returned because there are three groups
of rows with the same race_date column value. The value returned is the
first value that is found for the
group. race_date | race_time
------------+--------------------
2019-03-21 | 10:01:18.000000000
2018-07-26 | 10:01:18.000000000
2017-04-14 | 10:01:18.000000000
(3 rows)race_date and FLOOR(race_time,
1h), which returns the hour. The number of rows in each group is returned by
COUNT(*).SELECT race_date, FLOOR(race_time, 1h), COUNT(*) FROM cycling.race_times_summary GROUP BY race_date, FLOOR(race_time, 1h);Nine rows are returned because there are nine groups of rows with the same
race_date and FLOOR(race_time, 1h)
values: race_date | system.floor(race_time, 1h) | count
------------+-----------------------------+-------
2019-03-21 | 10:00:00.000000000 | 2
2019-03-21 | 11:00:00.000000000 | 1
2019-03-21 | 12:00:00.000000000 | 1
2018-07-26 | 10:00:00.000000000 | 2
2018-07-26 | 11:00:00.000000000 | 1
2018-07-26 | 12:00:00.000000000 | 1
2017-04-14 | 10:00:00.000000000 | 2
2017-04-14 | 11:00:00.000000000 | 1
2017-04-14 | 12:00:00.000000000 | 1
(9 rows)Computing aggregates
DSE provides standard built-in functions that return aggregate values to
SELECT statements.
Using COUNT() to get the non-null value count for a column
A SELECT expression using COUNT(column_name) returns
the number of non-null values in a column. COUNT ignores null values.
For example, count the number of last names in the cyclist_name
table:
SELECT COUNT(lastname) FROM cycling.cyclist_name;
Getting the number of matching rows and aggregate values with COUNT()
A SELECT expression using COUNT(*) returns the number
of rows that matched the query. Use COUNT(1) to get the same result.
COUNT(*) or COUNT(1) can be used in conjunction with
other aggregate functions or columns.
This example counts the number of rows in the cyclist name table:
SELECT COUNT(*) FROM cycling.cyclist_name;
This example calculates the maximum value for start day in the cycling events table and counts the number of rows returned:
SELECT start_month, MAX(start_day), COUNT(*) FROM cycling.events WHERE year = 2017 AND discipline = 'Cyclo-cross';
This example provides a year that is not stored in the events table:
SELECT start_month, MAX(start_day) FROM cycling.events WHERE year = 2022 ALLOW FILTERING;
start_month | system.max(start_day)
-------------+-----------------------
null | null
(1 rows)Getting maximum and minimum values in a column
SELECT expression using
MAX(column_name) returns the maximum value in a
column. When the column's data type is numeric (bigint,
decimal, double, float,
int, or smallint), this returns the maximum value.
SELECT MAX(race_points) FROM cycling.cyclist_points WHERE id = e3b19ec4-774a-4d1c-9e5a-decec1e30aac;
system.max(race_points)
-------------------------
120WHERE clause, a warning message is displayed:
Warnings :
Aggregation query used without partition keyMIN function returns the minimum
value:SELECT MIN(race_points) FROM cycling.cyclist_points WHERE id = e3b19ec4-774a-4d1c-9e5a-decec1e30aac;
system.min(race_points)
-------------------------
6If the column referenced by MAX or MIN has an
ascii or text data type, these functions return the
last or first item in an alphabetic sort of the column values. If the specified column has
data type date or timestamp, these functions return the
most recent or least recent times and dates. If a column has a null value,
MAX and MIN ignores that value; if the column for an
entire set of rows contains null, MAX and MIN return
null.
If the query includes a WHERE clause (recommended), MAX
or MIN returns the largest or smallest value from the rows that satisfy
the WHERE condition.
Getting the average or sum of a column of numbers
DSE computes the average of all values in a column when AVG is used in
the SELECT statement:
SELECT AVG(race_points) FROM cycling.cyclist_points WHERE id = e3b19ec4-774a-4d1c-9e5a-decec1e30aac;
system.avg(race_points)
-------------------------
67Using SUM to get a total:
SELECT SUM(race_points)
FROM cycling.cyclist_points
WHERE id = e3b19ec4-774a-4d1c-9e5a-decec1e30aac; system.sum(race_points)
-------------------------
201
(1 rows)If any of the rows returned have a null value for the column referenced for a
SUM or AVG aggregation function, the function includes
that row in the row count, but uses a zero value to calculate the average. The
SUM and AVG functions do not work with
text, uuid, or date fields.
Retrieving the date/time a write occurred
The WRITETIME function applied to a column returns the date/time in microseconds at which the column was written to the database.
For example, to retrieve the date/time that writes occurred to the firstname column of a cyclist:
SELECT WRITETIME (firstname) FROM cycling.cyclist_points WHERE id = e3b19ec4-774a-4d1c-9e5a-decec1e30aac;
writetime(firstname)
----------------------
1538688876521481
1538688876523973
1538688876525239The WRITETIME output of the last write 1538688876525239
in microseconds converts to Thursday, October 4, 2018 4:34:36.525 PM GMT-05:00
DST.
Retrieving the time-to-live of a column
INSERT INTO cycling.calendar ( race_id, race_name, race_start_date, race_end_date ) VALUES ( 200, 'placeholder', '2015-05-27', '2015-05-27' ) USING TTL 100;
UPDATE cycling.calendar USING TTL 300 SET race_name = 'dummy' WHERE race_id = 200 AND race_start_date = '2015-05-27' AND race_end_date = '2015-05-27';After inserting the TTL, use SELECT statement to check its current value:
SELECT TTL(race_name) FROM cycling.calendar WHERE race_id = 200;Output:
ttl(race_name)
----------------
276
(1 rows) Retrieving values in the JSON format
For details, see Retrieval using JSON
TRUNCATE
TRUNCATE [ TABLE ] [keyspace_name.]table_name ;Learn more.
Examples
- If necessary, use the cqlsh CONSISTENCY command to set the
consistency level to
ALL. - Use nodetool status or some other tool to make sure all nodes are up and receiving connections.
- Use TRUNCATE or TRUNCATE TABLE, followed by the
table
name.
TRUNCATE cycling.country_flag;
- Use SELECT to verify the table data has been
truncated.
SELECT * from cycling.country_flag ;
country | cyclist_name | flag ---------+--------------+------ (0 rows)
Unable to complete request: one or more nodes were unavailable.
UNRESTRICT
UNRESTRICT permission_name ON [keyspace_name.]table_name FROM role_name ;Learn more.
Examples
UNRESTRICT SELECT ON KEYSPACE cycling FROM db_admin;
UPDATE
UPDATE [keyspace_name.]table_name [ USING TTL time_value ] [ [ AND ] USING TIMESTAMP timestamp_value ] SET assignment [ , assignment ... ] WHERE row_specification [ ( IF EXISTS | IF condition [ AND condition ] ) ] ;Learn more.
Examples
Updating a column
UPDATE cycling.cyclist_name SET firstname = NULL WHERE id IN ( 5b6962dd-3f90-4c93-8f61-eabfa4a803e2, fb372533-eb95-4bb4-8685-6ef61e994caa );
UPDATE cycling.cyclist_name SET firstname = 'Marianne', lastname = 'VOS' WHERE id = 88b8fd18-b1ed-4e96-bf79-4280797cba80;
Updating a counter column
UPDATE cycling.popular_count SET popularity = popularity + 2 WHERE id = 6ab09bec-e68e-48d9-a5f8-97e6fb4c9b47;
To use a lightweight transaction on a counter column to ensure accuracy, put one or more counter updates in the batch statement. For details, see Performing conditional updates in a batch.
Creating a partition using UPDATE
cyclists table, whose primary key is (id), you can
UPDATE the partition with id e7cd5752-bc0d-4157-a80f-7523add8dbcd, even
though it does not exist
yet:UPDATE cycling.cyclist_name SET firstname = 'Anna', lastname = 'VAN DER BREGGEN' WHERE id = e7cd5752-bc0d-4157-a80f-7523add8dbcd;
Updating a list
UPDATE cycling.upcoming_calendar SET events = ['Criterium du Dauphine','Tour de Suisse'] WHERE year=2015 AND month=06;
UPDATE cycling.upcoming_calendar SET events = ['Tour de France'] + events WHERE year=2015 AND month=06;
UPDATE cycling.upcoming_calendar SET events = events + ['Tour de France'] WHERE year=2017 AND month=05;
UPDATE cycling.upcoming_calendar SET events[2] = 'Tour de France' WHERE year=2015 AND month=06;
UPDATE cycling.upcoming_calendar SET events = events - ['Tour de France'] WHERE year=2015 AND month=06;
To update data in a collection column of a user-defined type, enclose components of the type in parentheses within the curly brackets, as shown in "Using a user-defined type."
set or
map collection types are safer for updates.Updating a set
UPDATE cycling.cyclist_career_teams
SET teams = teams + {'Team DSB - Ballast Nedam'}
WHERE id = 5b6962dd-3f90-4c93-8f61-eabfa4a803e2;UPDATE cycling.cyclist_career_teams
SET teams = teams - {'DSB Bank Nederland bloeit'}
WHERE id = 5b6962dd-3f90-4c93-8f61-eabfa4a803e2;UPDATE cycling.cyclist_career_teams
SET teams = {}
WHERE id = 5b6962dd-3f90-4c93-8f61-eabfa4a803e2;Updating a map
UPDATE cycling.upcoming_calendar
SET description = description + {'Criterium du Dauphine' : 'Easy race'}
WHERE year = 2015 AND month = 06 ;events:UPDATE cycling.upcoming_calendar SET events[2] = 'Vuelta Ciclista a Venezuela' WHERE year = 2015 AND month = 06;
UPDATE cycling.upcoming_calendar USING TTL 10000000 SET events[2] = 'Vuelta Ciclista a Venezuela' WHERE year = 2015 AND month = 06;
UPDATE cycling.upcoming_calendar
SET description = description + {'Criterium du Dauphine' : 'Easy race', 'Tour du Suisse' : 'Hard uphill race'}
WHERE year = 2015 AND month = 6;Remove elements from a map in the same way using - instead of +.
About updating sets and maps caution
CQL supports alternate methods for updating sets and maps. These alternatives may seem to accomplish the same tasks, but the database handles them differently in important ways.
UPDATE cycling.upcoming_calendar
SET description =
{'Criterium du Dauphine' : 'Easy race',
'Tour du Suisse' : 'Hard uphill race'}
WHERE year = 2015 AND month = 6;The easiest way to add a new entry to the map is to use the + operator
as described above.
You may, however, try to add the new entry with a command that overwrites the first two and adds the new one.
These two statements seem to do the same thing. But behind the scenes, the database processes the second statement by deleting the entire collection and replacing it with a new collection containing three entries. This creates tombstones for the deleted entries, even though these entries are identical to the entries in the new map collection. If your code updates all map collections this way, it generates many tombstones, which may slow the system down.
The examples above use map collections, but the same caution applies to updating sets.
Updating a UDT with non-collection fields
UPDATE cycling.cyclist_stats SET basics.birthday = '2000-12-12' WHERE id = 220844bf-4860-49d6-9a4b-6b5d3a79cbfb;
Conditionally updating columns
You can conditionally update columns using IF or IF EXISTS.
UPDATE cycling.cyclist_id SET id = UUID() WHERE lastname = 'WELTEN' AND firstname = 'Bram' AND age = 18 IF EXISTS;
- If the row exists (returns true), the following is output:
[applied] ----------- True -
If no row exists (returns false), the command fails and the following is output:
[applied] ----------- False
Use IF condition to apply tests to one or more other (non-primary key) column values in the matching row.
UPDATE cycling.cyclist_id SET id = UUID() WHERE lastname = 'WELTEN' AND firstname = 'Bram' AND age = 18 IF id = 18f471bf-f631-4bc4-a9a2-d6f6cf5ea503;
- If a record matches and the condition returns TRUE, the update is applied and
following is
output:
[applied] ----------- True - If a record matches and the condition returns false, the query fails and following
shows an example of the
output:
[applied] | id -----------+-------------------------------------- False | 863e7103-c03b-48c3-a11c-42376aa77291 - If no record matches and the condition is testing for a non-null value such as
id = 18f471bf-f631-4bc4-a9a2-d6f6cf5ea503the query also fails.
IF condition tests for a null value, for example:UPDATE cycling.cyclist_id SET id = UUID() WHERE lastname = 'Smith' AND firstname = 'Joe' AND age = 22 IF id = NULL;
- A record matches and the id column has no value, a value is inserted.
- A record matches and the id column has a value (is not null), the statement fails.
- No record matches, then a new record is created.
Performing conditional updates in a BATCH
The UPDATE command creates a new row if no matching row is found. New rows are not immediately available for lightweight transactions applied in the same BATCH.
For example:
CREATE TABLE cycling.mytable (a int, b int, s int static, d text, PRIMARY KEY (a, b));
BEGIN BATCH
INSERT INTO cycling.mytable (a, b, d) values (7, 7, 'a');
UPDATE cycling.mytable SET s = 7 WHERE a = 7 IF s = NULL;
APPLY BATCH;
In the first batch above, the insert command creates a partition with
primary key values (7,7) but does not set a value for the s column. Even
though the s column was not defined for this row, the IF s =
NULL conditional succeeds, so the batch succeeds. (In previous versions, the
conditional would have failed, and that failure would have caused the entire batch to
fail.)
USE
USE keyspace_name ;Learn more.
Example
USE cycling;