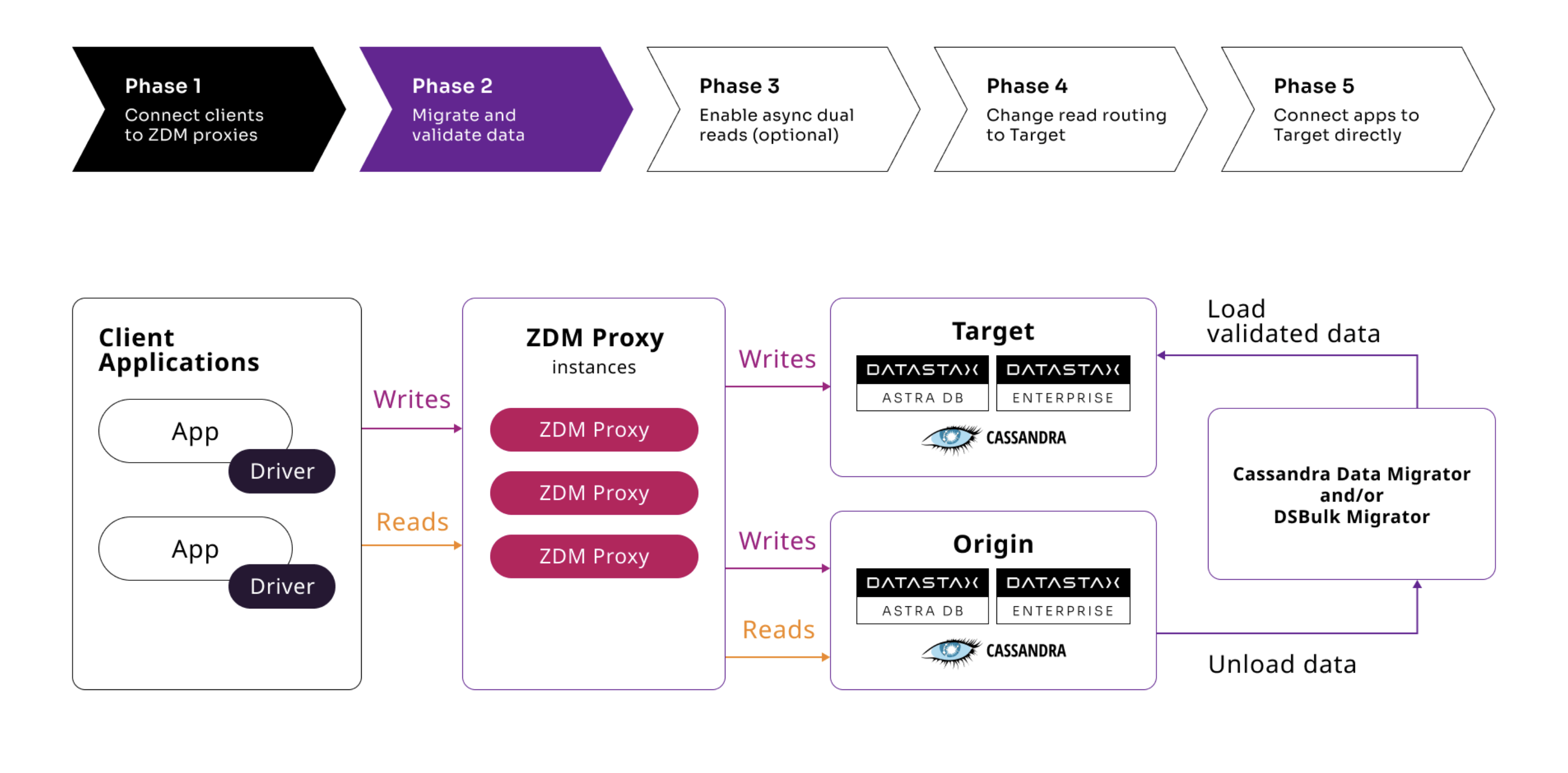
Phase 2: Migrate and validate data
This topic introduces two open-source data migration tools that you can use during Phase 2 of your migration project.
For full details, see these topics:
These tools provide sophisticated features that help you migrate your data from any Cassandra Origin (Apache Cassandra®, DataStax Enterprise (DSE), DataStax Astra DB) to any Cassandra Target (Apache Cassandra, DSE, DataStax Astra DB).
What’s the difference between these data migration tools?
In general:
-
Cassandra Data Migrator (CDM) is the best choice to migrate large data quantities, and where detailed logging, data verifications, table column renaming (if needed), and reconciliation options are provided.
-
DSBulk Migrator leverages DataStax Bulk Loader (DSBulk) to perform the data migration, and provides new commands specific to migrations. DSBulk Migrator is ideal for simple migration of smaller data quantities, and where data validation (other than post-migration row counts) is not necessary.
Open-source repos with essential data migration tools
Refer to the following GitHub repos:
-
Cassandra Data Migrator repo.
-
DSBulk Migrator repo.
A number of helpful assets are provided in each repo.
In particular, the CDM repo provides two configuration templates, with embedded comments and default values, which you can customize to match your data migration’s requirements:
-
cdm.properties provides a subset of configuration options with commonly required settings.
-
cdm-detailed.properties with all available options.
Cassandra Data Migrator features
CDM offers functionalities like bulk export, import, data conversion, mapping of column names between Origin and Target, and validation. The CDM capabilities are extensive:
-
Automatic detection of each table’s schema - column names, types, keys, collections, UDTs, and other schema items.
-
Validation - Log partitions range-level exceptions, use the exceptions file as input for rerun operations.
-
Supports migration of Counter tables.
-
Preserves writetimes and Time To Live (TTL).
-
Validation of advanced data types - Sets, Lists, Maps, UDTs.
-
Filter records from Origin using writetimes, and/or CQL conditions, and/or a list of token ranges.
-
Guardrail checks, such as identifying large fields.
-
Fully containerized support - Docker and Kubernetes friendly.
-
SSL support - including custom cipher algorithms.
-
Migration/validation from and to Azure Cosmos Cassandra.
-
Validate migration accuracy and performance using a smaller randomized data-set.
-
Support for adding custom fixed writetime.
With new or enhanced capabilities in recent CDM v4.x releases.
-
Column names can differ between Origin and Target.
-
UDTs can be migrated from Origin to Target, even when the keyspace names differ.
-
Predefined Codecs allow for data type conversion between Origin and Target; you can add custom Codecs.
-
Separate Writetime and TTL configuration supported. Writetime columns can differ from TTL columns.
-
A subset of columns can be specified with Writetime and TTL: Not all eligible columns need to be used to compute the Origin value.
-
Automatic
RandomPartitionermin/max: Partition min/max values no longer need to be manually configured. -
You can populate Target columns with constant values: New columns can be added to the Target table, and populated with constant values.
-
Expand Origin Map Column into Target rows: A Map in Origin can be expanded into multiple rows in Target when the Map key is part of the Target primary key.
For extensive usage and reference details, see Cassandra Data Migrator.
DSBulk Migrator features
DSBulk Migrator, which is based on DataStax Bulk Loader (DSBulk), is best for migrating smaller amounts of data, and/or when you can shard data from table rows into more manageable quantities.
DSBulk Migrator provides the following commands:
-
migrate-livestarts a live data migration using a pre-existing DSBulk installation, or alternatively, the embedded DSBulk version. A "live" migration means that the data migration will start immediately and will be performed by this migrator tool through the desired DSBulk installation. -
generate-scriptgenerates a migration script that, once executed, will perform the desired data migration, using a pre-existing DSBulk installation. Please note: this command does not actually migrate the data; it only generates the migration script. -
generate-ddlreads the schema from Origin and generates CQL files to recreate it in an Astra DB cluster used as Target.
For extensive usage and reference details, see DSBulk Migrator.